Windows 文件系统
转载自:嘿_lele
链接:https://www.jianshu.com/p/8471b7f4152a
来源:简书
硬盘上的一个物理记录块要用三个参数来定位:柱面号、扇区号、磁头号。
表示硬盘总共有几个磁头,也就是有几面盘片, 最大为 255 (用 8 个二进制位存储);
当磁盘旋转时,磁头若保持在一个位置上,则每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道。
磁盘上的每个磁道被等分为若干个弧段,这些弧段便是磁盘的扇区,表示每一条磁道上有几个扇区, 最大为 63(用 6个二进制位存储);每个扇区一般是 512个字节,理论上讲这不是必须的,但(由于不断提高磁盘的大小,部分厂商设定每个扇区的大小是4096字节)。距离轴心近的磁道上包含的扇区比远的磁道要少很多。硬盘的读写以扇区为基本单位。
是指硬盘多个盘片上相同磁道的组合,盘片上的同心圆(磁道)圈数即是柱面数。表示硬盘每一面盘片上有几条磁道;硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的“0”开始编号,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面。磁盘的柱面数与一个盘面上的磁道数是相等的。由于每个盘面都有自己的磁头,因此,盘面数等于总的磁头数。当向一个磁盘读写数据的时候,如果是连续IO,磁盘会比较倾向于按照柱面来进行,因为写完一个盘片的磁道,切换到另外一个盘片的相同磁道,只需要切换磁头就可以了,如果是连续在一个盘片上写几个磁道,就涉及到磁臂换道,这个是机械动作 ,就慢的多了,如果是离散IO,那磁臂基本就像振动的蜜蜂翅膀.
磁盘生产出来的时候,上面是没有什么磁道,扇区的东西的,低级格式化就是在每个盘片上划分,标明这些东西,而高级格式化,比如 WINDOWS 里面的格式化,他是绝对不会影响一个磁盘的磁道,扇区结构的,这好比低级格式化是造房子,打框架,高级格式化是给房子里面做装潢
所以磁盘一柱面:512byte x 63 x 255=8225280bytes =7.84423828125 MB
硬盘容量 = 磁头数 × 柱面数(磁道数)× 扇区数 × 512字节,扇区越多,容量越大。
磁盘块/簇(虚拟出来的)。 块是操作系统中最小的逻辑存储单位。操作系统与磁盘打交道的最小单位是磁盘块。通俗的来讲,在 Windows 下如 NTFS 等文件系统中叫做簇;在 Linux 下如 Ext4 等文件系统中叫做块(block)。每个簇或者块可以包括2、4、8、16、32、64…2的n次方个扇区
- 扇区: 硬盘的最小读写单元
- 块/簇: 是操作系统针对硬盘读写的最小单元
- page: 是内存与操作系统之间操作的最小单元。
- 扇区 <= 块/簇 <= page
分区表是将大表的数据分成称为分区的许多小的子集,类型有 FAT32, NTFST32,NTFS。另外,分区表的种类划分主要有:range,list,和hash分区。划分依据主要是根据其表内部属性。同时,分区表可以创建其独特的分区索引。倘若硬盘丢失了分区表,数据就无法按顺序读取和写入,导致无法操作。
| 偏移 | 长度(字节) | 意义 |
|---|---|---|
| 00H | 1 | 分区状态:00->非活动分区;80->活动分区;其他数值没有意义 |
| 01H | 1 | 分区起始磁头号(HEAD),用到全部8位 |
| 02H | 2 | 分区起始扇区号(SECTOR),占据02H的位0-5;该分区的起始磁柱号(CYLINDER),占据02H的位6-7和03H的全部8位 |
| 04H | 1 | 文件系统标志 |
| 05H | 1 | 分区结束磁头号(HEAD),用到全部8位 |
| 06H | 2 | 分区结束扇区号(SECTOR),占据06H的位0-5;该分区的起始磁柱号(CYLINDER),占据06H的位6-7和07H的全部8位 |
| 08H | 4 | 分区起始相对扇区号 |
| 0CH | 4 | 分区总的扇区数 |

传统的分区方案(称为 MBR 分区方案)是将分区信息保存到磁盘的第一个扇区(MBR扇区)中的64个字节中,每个分区项占用16个字节,这16个字节中存有活动状态标志、文件系统标识、起止柱面号、磁头号、扇区号、隐含扇区数目(4个字节)、分区总扇区数目(4个字节)等内容。由于MBR扇区只有64个字节用于分区表,所以只能记录4个分区的信息。这就是硬盘主分区数目不能超过4个的原因。后来为了支持更多的分区,引入了扩展分区及逻辑分区的概念。但每个分区项仍用16个字节存储。
主分区数目不能超过 4 个的限制,很多时候,4 个主分区并不能满足需要。另外最关键的是 MBR 分区方案无法支持超过 2TB 容量的磁盘。因为这一方案用 4 个字节存储分区的总扇区数,最大能表示 2 的 32 次方的扇区个数,按每扇区 512 字节计算,每个分区最大不能超过 2TB。磁盘容量超过 2TB 以后,分区的起始位置也就无法表示了。在硬盘容量突飞猛进的今天,2TB的限制早已被突破。由此可见,MBR 分区方案现在已经无法再满足需要了。
一种由基于 Itanium 计算机中的可扩展固件接口 (EFI) 使用的磁盘分区架构。与主启动记录(MBR) 分区方法相比,GPT 具有更多的优点,因为它允许每个磁盘有多达 128 个分区,支持高达 18 千兆兆字节的卷大小,允许将主磁盘分区表和备份磁盘分区表用于冗余,还支持唯一的磁盘和分区 ID (GUID)。 与支持最大卷为 2 TB (terabytes) 并且每个磁盘最多有 4 个主分区(或 3 个主分区,1 个扩展分区和无限制的逻辑驱动器)的主启动记录 (MBR) 磁盘分区的样式相比,GUID 分区表 (GPT) 磁盘分区样式支持最大卷为 18 EB (exabytes,1EB=1024PB,1PB=1024TB,1TB=1024GB,1GB=1024MB,1MB=1024KB。18EB=19 327 352 832GB) 并且每磁盘最多有 128 个分区。与 MBR 分区的磁盘不同,至关重要的平台操作数据位于分区,而不是位于非分区或隐藏扇区。另外,GPT 分区磁盘有多余的主要及备份分区表来提高分区数据结构的完整性。
一个 ntfs 文件系统由引导扇区、主文件表MFT(包含MFT元数据)和数据区组成。
NTFS中存储了两份 MFT 备份以防 MFT 文件损坏,两 MFT 备份(备份在数据区)的具体起始位置都存储在引导扇区中。
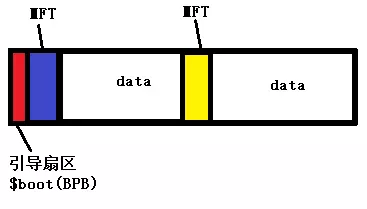
引导扇区是从NTFS文件系统的第一个扇区开始,以55 AA结尾。我们主要关注前88字节的信息,其中重要的就是“NTFS”标识、扇区大小、每簇扇区数、MFT起始簇以及MFT备份MFTMirr位置这些信息。我们可以根据MFT起始簇信息找到MFT,或者根据MFT备份MFTMirr位置找到MFT的另外一个MFT备份。如下图所示:

第0个扇区数据 buf 偏移0x03开始的8个Bytes就是"NTFS “,表示这个扇区就是NTFS的引导记录。这第0个扇区也就是$Boot扇区,这个扇区包含了该卷的 BPB 和扩展BPB参数,可以得到该卷的卷大小,磁头数,扇区大小,簇大小等等参数;要解析一个NTFS卷的文件结构也是从这里的BPB参数开始的。解析时有用到的是这个扇区的前 88 (0x58) 个Bytes,剩余的是引导代码和结束标志"55 AA”,前88个字节具体结构如下:

typedef struct NTFS_BPB{ // 在cmd 输入 fsutil fsinfo ntfsinfo d: 查询 NTFS 信息
UCHAR jmpCmd[3];
UCHAR s_ntfs[8]; // "NTFS " 标志
// 0x0B
UCHAR bytesPerSec[2]; // 0x0200 扇区大小,512B
UCHAR SecsPerClu; // 0x08 每簇扇区数,4KB
UCHAR rsvSecs[2]; // 保留扇区
UCHAR noUse01[5]; //
// 0x15
UCHAR driveDscrp; // 0xF8 磁盘介质 -- 硬盘
UCHAR noUse02[2]; //
// 0x18
UCHAR SecsPerTrack[2]; // 0x003F 每道扇区数 63
UCHAR Headers[2]; // 0x00FF 磁头数
UCHAR secsHide[4]; // 0x3F 隐藏扇区
UCHAR noUse03[8]; //
// 0x28
UCHAR allSecsNum[8]; // 卷总扇区数, 高位在前, 低位在后
// 0x30
UCHAR MFT_startClu[8]; // MFT 起始簇
UCHAR MFTMirr_startClu[8]; // MTF 备份 MFTMirr 位置
//0x40
UCHAR cluPerMFT[4]; // 每记录簇数 0xF6
UCHAR cluPerIdx[4]; // 每索引簇数
//0x48
UCHAR SerialNum[8]; // 卷序列号
UCHAR checkSum[8]; // 校验和
}Ntfs_Bpb,*pNtfs_Bpb;
在一个分区中引导记录扇区所在的簇编号为0,往后的簇编号1,2,3等等一直到卷尾,这就是一个分区的逻辑簇号(LCN);计算
逻辑扇区号:LCN * 簇大小,簇的大小在BPB参数中找到,一般为8个扇区4KB;以此可以由 MFT 起始簇 MFT_startClu 计算出第一个 MFT 项(记录)的位置。
VCN,虚拟簇号,给一个文件从它的首簇开始编号,为0,依次递增一直到文件的尾簇,在物理上不一定连续
MFT 是由一条条 MFT 项(记录)所组成的,而且每项大小是固定的(一般为1KB),MFT保留了前16项用于特殊文件记录,称为元数据,元数据在磁盘上是物理连续的,编号为0~15;如果$MFT的偏移为0x0C0000000,那么下一项的偏移就是0x0C0000400,在下一项就是 0x0C0000800等等;
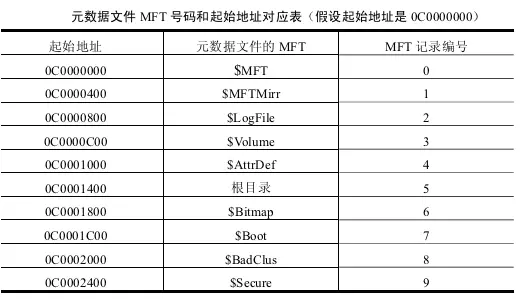
MFT记录了整个卷的所有文件信息(包括MFT本身、数据文件、文件夹等等)信息,包括空间占用,文件基本属性,文件位置索引,创建时间用户权限,加密信息等等,都存储在MFT。每一个文件在 MFT 中都有一个或多个 MFT 项记录文件属性信息。这里的属性包括数据,如果这个文件很小在 MFT 项中就可以放下,那么这条属性就定义为常驻属性,常驻标志位记为1,如果是非常驻,则有一个索引指向另一条记录(称为一个运行)。
MFT 的第一项记录$MFT描述的是主分区表MFT本身,它的编号为0,MFT项的头部都是如下结构:
- 在一个MFT项中前56字节是MFT头部信息,其中比较重要的是FILE标识、第一个属性的偏移和flags。
- flags 显示了此文件是否是正常文件,或者是删除文件等。
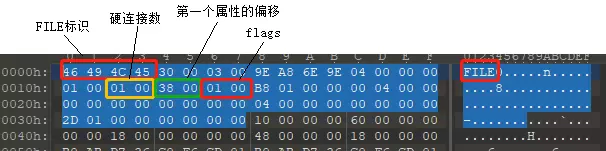

typedef struct MFT_HEADER{
UCHAR mark[4]; // "FILE" 标志
UCHAR UsnOffset[2]; // 更新序列号偏移 30 00
UCHAR usnSize[2]; // 更新序列数组大小+1 03 00
UCHAR LSN[8]; // 日志文件序列号(每次记录修改后改变) 58 8E 0F 34 00 00 00 00
// 0x10
UCHAR SN[2]; // 序列号 随主文件表记录重用次数而增加
UCHAR linkNum[2]; // 硬连接数 (多少目录指向该文件) 01 00
UCHAR firstAttr[2]; // 第一个属性的偏移 38 00
UCHAR flags[2]; // 0已删除 1正常文件 2已删除目录 3目录正使用
// 0x18
UCHAR MftUseLen[4]; // 记录有效长度 A8 01 00 00
UCHAR maxLen[4]; // 记录占用长度 00 04 00 00
// 0x20
UCHAR baseRecordNum[8]; // 索引基本记录, 如果是基本记录则为0
UCHAR nextAttrId[2]; // 下一属性Id 07 00
UCHAR border[2]; //
UCHAR xpRecordNum[4]; // 用于xp, 记录号
// 0x30
UCHAR USN[8]; // 更新序列号(2B) 和 更新序列数组
}Mft_Header, *pMft_Header;
上面的头部结构体在扇区的数据偏移 0x00 ~0x38;
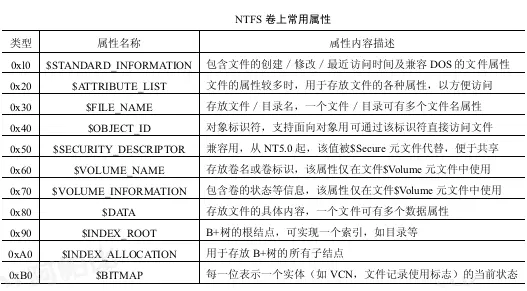
在0x38之后的4大块颜色数据是4条属性,描述名称,时间,索引等等信息,最后以"FF FF FF FF"结束。它们分别以0x10,0x30, 0x80, 0xB0作为标志;这里的四种属性所描述的的信息类型可以由下表查得,对照数据和结构体可以把这4条属性解析出来。
每条属性都包含属性头和属性结构。每条属性的前4字节显示该属性的类型,不同类型的属性有不同的属性结构。
//------------------ 属性头通用结构 ----
typedef struct NTFSAttribute //所有偏移量均为相对于属性类型 Type 的偏移量
{
UCHAR Type[4]; // 属性类型 0x10, 0x20, 0x30, 0x40,...,0xF0,0x100
UCHAR Length[4]; // 属性的长度
UCHAR NonResidentFiag; // 是否是非常驻属性,l 为非常驻属性,0 为常驻属性 00
UCHAR NameLength; // 属性名称长度,如果无属性名称,该值为 00
UCHAR ContentOffset[2]; // 属性内容的偏移量 18 00
UCHAR CompressedFiag[2]; // 该文件记录表示的文件数据是否被压缩过 00 00
UCHAR Identify[2]; // 识别标志 00 00
//--- 0ffset: 0x10 ---
//-------- 常驻属性和非常驻属性的公共部分 ----
union CCommon
{
//---- 如果该属性为 常驻 属性时使用该结构 ----
struct CResident
{
UCHAR StreamLength[4]; // 属性值的长度, 即属性具体内容的长度。"48 00 00 00"
UCHAR StreamOffset[2]; // 属性值起始偏移量 "18 00"
UCHAR IndexFiag[2]; // 属性是否被索引项所索引,索引项是一个索引(如目录)的基本组成 00 00
};
//------- 如果该属性为 非常驻 属性时使用该结构 ----
struct CNonResident
{
UCHAR StartVCN[8]; // 起始的 VCN 值(虚拟簇号:在一个文件中的内部簇编号,0起)
UCHAR LastVCN[8]; // 最后的 VCN 值
UCHAR RunListOffset[2]; // 运行列表的偏移量
UCHAR CompressEngineIndex[2]; // 压缩引擎的索引值,指压缩时使用的具体引擎。
UCHAR Reserved[4];
UCHAR StreamAiiocSize[8]; // 为属性值分配的空间 ,单位为B,压缩文件分配值小于实际值
UCHAR StreamRealSize[8]; // 属性值实际使用的空间,单位为B
UCHAR StreamCompressedSize[8]; // 属性值经过压缩后的大小, 如未压缩, 其值为实际值
};
};
};
由这个结构体可以知道,属性头的长度取决于是否有属性名,属性名长度是多少;是否常驻,如果常驻,属性内容长度是多少,如果非常驻,运行列表有多长。
(0x08)日志文件序列号,它又叫文件参考号、文件引用号,一共 8Byte,前6个字节是文件称为文件号;后2个字节是文件顺序号,文件顺序号随重用而增加
- 具体属性头的大小根据是否是常驻属性来进行计算。
- 是否是常驻属性根据属性头的第9个字节判断,1为非常驻,0为常驻。
- 如果是非常驻属性,属性头大小为64;如果是常驻属性,属性头大小为24字节。
- 常驻和非常驻的区别:
- 常驻属性是直接保存再MFT中,非常驻属性保存再MFT之外的其他地方。如果文件或文件夹小于1500字节,那么它们的所有属性,包括内容都会常驻在MFT中。
不同类型的属性有不同的属性结构,这里主要介绍10H属性、30H属性和80H属性。
10H属性$STANDART_INFORMATION,描述的是文件的创建、访问、修改时间,传统属性,以及版本信息等等。
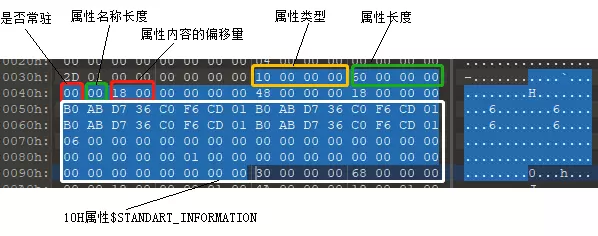
struct Value0x10
{
UCHAR fileCreateTime[8]; // 文件创建时间
UCHAR fileChangeTime[8]; // 文件修改时间
UCHAR MFTChangeTime[8]; // MFT修改时间
UCHAR fileLatVisited[8]; // 文件最后访问时间
UCHAR tranAtrribute[4]; // 文件传统属性
UCHAR otherInfo[28]; // 版本,所有者,配额,安全等等信息(详细略)
UCHAR updataNum[8]; // 文件更新序列号
};
下面的偏移都是相对于属性首字节,其值加上0x38 就是实际偏移(图中的offset)。
- 0x00 4B: (0x10) 类型标志
- 0x04 4B: (0x60) 整条10H属性的长度
- 0x08 1B: (0x00) 非常驻
- 0x09 1B: (0x00) 无属性名称
- 0x0A 2B: (0x18) 属性内容偏移位置
- 0x18 8B: (ED 46 39 6B 6B 93 CF 01) 8个字节是文件创建时间,紧随其后的3x8个字节分别是文件最后修改时间,MFT修改时间,文件最后访问时间。64位数值是相对于1601-01-01零点整的千万分之一秒数。可以用FileTimeToSystemTime()转换成我们通常见到的形式。
- 0x38 8B: (06 00 00 00 00 00 00 00)传统属性,这里是系统隐含文件,位描述:

后面还有0x28个字节是版本和管理信息等等。
当一个文件需要多个MFT项来记录,20H是用来描述属性的属性列表;当非常驻属性依然不够空间,则需要属性列表。20H类属性也有可能为常驻或非常驻,可以应用上面的通用属性头。以此结构体得到属性值的偏移地址,进而得到属性内容。
//------- 这个结构只是数据内容部分,不包括属性头 NTFSAttribute ----
//------- 由属性头的属性值偏移量确定属性值的起始位置 ---
struct Value0x20{
UCHAR type[4]; // 类型
UCHAR recordType[2]; // 记录类型
UCHAR nameLen[2]; // 属性名长度
UCHAR nameOffset; // 属性名偏移
UCHAR startVCN[8]; // 起始 VCN
UCHAR baseRecordNum[8]; // 基本文件记录索引号
UCHAR attributeId[2]; // 属性 id
//---- 属性名(Unicode) 长度取决于 nameLen 的值 ---
};
这个属性比较重要,包含了文件的详细资料和父目录的参考号等。根据父目录参考号可以知道文件之间的父子关系,从而构建文件的子父关系。
其实在10H属性中已经描述了文件的部分信息(时间、标志等),30H属性主要关注父目录的参考号、文件名命名空间和文件名。
30H 类型属性描述的是文件或文件夹的名字和创建基本信息,属性头不在赘述,属性值的结构如下:

struct Value0x30
{
UCHAR parentFileNum[8]; // 父目录的文件参考号,前 6B 的文件记录号,后 2B 的文件引用计数;当文件记录号为0x05时,是根目录。
UCHAR createTime[8]; // 文件创建时间
UCHAR changeTime[8]; // 文件修改时间
UCHAR MFTchangeTime[8]; // MFT 修改时间
UCHAR lastVisitTime[8] // 最后一次访问时间
UCHAR AllocSize[8]; // 文件分配大小
UCHAR realSize[8]; // 实际大小
UCHAR fileFlag[4]; // 文件标志,系统 隐藏 压缩等等
UCHAR EAflags[4] // EA扩展属性和重解析点
UCHAR nameLength; // 文件名长
UCHAR nameSpace; // 文件命名空间:0 --- POSIX, 1 -- Win32, 2 --- DOS, 3 --- Win32 & DOS
//----- Name (Unicode编码) 长度为 2 * nameLength ----
}
NTFS通过为一个文件创建多个30H属性实现POSIX (Portable Operating System Interface, 可移植操作系统接口) 式硬连接,每个30H属性都有自己的详细资料和父目录;一个硬连接删除时,就从MFT中删除这个文件名,最后一个硬连接被删除时,这个文件就算是真正被删除了。
MTFS统一给所有 MFT 记录分配的一个标识 — 对象ID,即结构体第一个16B,可能只有一个全局对象ID,后面的3个ID可能没有。
struct Value0x40
{
UCHAR GObjectId[16]; // 全局对象ID 给文件的唯一ID号
UCHAR GOriginalVolumeId[16]; // 全局原始卷ID 永不改变
UCHAR GOriginalObjectId[16]; // 全局原始对象ID 派给本MFT记录的第一个对象ID
UCHAR GDomain[16]; // 全局域ID (未使用)
};
struct Value0x60
{
//---- 通用属性头 --
UCHAR VolumeName[N]; //(Unicode) N 最大为 127 外加一个结束符'\0'
};
struct Value0x70
{ //----- 通用属性头 ---
UCHAR noUsed1[8]; // 00
UCHAR mainVersion; // 主版本号 1--winNT, 3--Win2000/XP
UCHAR SecVersion; // 次版本号 当主为3, 0--win2000, 1--WinXP/7
UCHAR flag[2]; // 标志
UCHAR noUsed2[4]; // 00
};
/* flag:
* 0x0001 坏区标志 下次重启时chkdsk/f进行修复
* 0x0002 调整日志文件大小
* 0x0004 更新装载
* 0x0008 装载到 NT4
* 0x0010 删除进行中的USN
* 0x0020 修复对象 Ids
* 0x8000 用 chkdsk 修正卷
*/
80H 属性 $DATA 容纳文件数据(未命名数据流),文件的大小一般指是未命名数据流的大小,没有长度限制,当它为常驻时,数据长度最小。它的结构为属性头加上数据流,如果数据流太大,则标记为非常驻,以运行的方式索引到外部。例如找一个MP3文件,从它的MFT项中0x80属性中可以看到它一定是非常驻,它的运行所指向的一系列簇就是音乐文件数据流;
struct Value0x80
{
UCHAR len; // 低4位表示运行簇大小的len,高4位表示起始簇的len
UCHAR *filesize; // 运行簇大小
UCHAR *start; // 起始簇 LCN/VCN
}
每个运行列表中第一个字节的低4位表示运行簇大小(filesize)的len,高4位表示起始簇(start)的len。如果一个运行列表后面的第一个字节是00,说明运行列表结束,后面的数值暂时不用管;如果不是00,则是下一个运行列表开始。

0x00~0x3F 是属性头;运行列表在橘黄色框中,0x40开始,可以得到运行列表 33 40 BC 00 00 00 0C。
- 首先0x33,低4位是3,表示紧随其后的3Byte 0xBC40作为运行簇大小(簇个数),即文件所占总大小;高4位是3,表示簇大小之后的3个Byte 0x0C0000 是起始簇,即文件起始,这里是说的是LCN。

- 第一个运行列表,首先是0x31,低4位是1,表示紧接着的1Byte(03)是运行簇大小;高4位是3,表示紧接着3Byte(65 9A 00)是起始簇,这里说的是LCN;
- 第二个运行列表,首先是0x11,低4位是1,表示紧接着的1Byte(01)是运行簇大小;高4位是1,表示紧接着3Byte(13)是起始簇,这里说的是VCN。
- 注意,只有第一个运行列表的起始簇说的是LCN,从第二个运行列表开始每个运行列表的起始簇都说的是VCN。想要得到LCN需要按下面的公式计算:
- 第n个运行列表的LCN = 第一个运行列表的起始簇(LCN) + 第二个运行列表的起始簇(VCN) +…+第n个运行列表的起始簇(VCN)

$INDEX_ROOT 索引根。实现NTFS的B+树索引的根节点,总是常驻。索引根属性由属性头、索引根和索引项组成。属性头是通用属性头的常驻部分。结构体如下(可能有些偏差):
struct indexHeader
{
UCHAR type[4]; // 属性类型
UCHAR checkRule[4]; // 校对规则
UCHAR allocSize[4]; // 索引项分配大小
UCHAR CluPerIdx; // 每索引记录的簇数
UCHAR noUse01[3]; // 填充
UCHAR firstIdxOffset[4]; // 第一个索引项偏移
UCHAR idxTotalSize[4]; // 索引项总大小
UCHAR indxAllocSize[4]; // 索引项分配大小
UCHAR flag; // 标志
UCHAR noUse02[3];
};
// 一般小目录在90属性中有常驻目录项,目录项的结构与INDX缓存中的目录项一样
struct indexItem
{
UCHAR MFTnum[8] // 文件的 MFT 记录号,前6B是MFT编号,用于定位此文件记录
UCHAR ItemLen:[2]; // 索引项大小
UCHAR IndexIdentifier:[2]; // 索引标志 R
UCHAR isNode[2]; // 1---此索引包含一个子节点,0---此为最后一项
UCHAR noUse03[2]; // 填充
UCHAR FMFTnum[8]; // 父目录 MFT文件参考号 0x05表示根目录
UCHAR CreateTime[8]; //文件创建时间
UCHAR fileModifyTime[8]; //文件修改时间
UCHAR MFTModifyTime[8]; //文件记录最后修改时间
UCHAR LastVisitTime[8]; //文件最后访问时间
UCHAR FileAllocSize[8]; //文件分配大小 (B)
UCHAR FileRealSize[8]; //文件实际大小 (B)
UCHAR FileIdentifier[8]; //文件标志
UCHAR FileNameLen; //文件名长度
UCHAR FileNameSpace; //文件名命名空间
//---- 0x52 ---
//FileName; // 文件名 (末尾填满 8 字节)
UCHAR nextItemVCN[8]; // 下一项的 VCN (有子节点才有)
};
A0H 属性 $INDEX_ALLOCATION 索引分配属性,也是索引,由属性头和运行列表组成,一般指向一个或多个目录文件(INDX文件,即4K缓存);
A0H属性和90H属性共同描述了磁盘文件和目录的 MFT 记录的位置。第5项MFT的A0H属性记录根目录的位置。
B0H 属性 $BITMAP 位图属性,虚拟簇使用(占用)情况,这条属性用在$MFT和索引中;在Bitmap文件中,每一个 Bit 代表分区的一个簇,置1代表其已使用;
第0个字节的第0位表示分区第0簇,之后依次递增。
C0H 属性 $REPARSE_POINT 重解析点。使应用程序为文件或目录关联一个应用程序数据块,详细略。
D0H $EA_INFORMATION 扩充信息属性。为在NTFS下实现HPFS的OS/2子系统信息,及WinNT服务器的OS/2客户端应用而设置的,一般为非常驻;
E0H $EA 扩充属性 也是为了实现NTFS下的 HPFS,一般为非常驻;
100H $LOGGED_UTILITY_STREAM,EFS加密属性,存储用于实现EFS加密有关的信息,合法用户列表,解密密钥等等
MFT文件是对NTFS中全部MFT(卷上的所有文件,包括文件名、时间戳、流名和数据流所在的群集号列表、索引、安全标识符以及诸如“只读”、“压缩”、“加密”之类的文件属性)的存储,可以根据MFT文件快速的查找卷上的所有文件;而MFTMirr文件是对MFT文件中比较重要项的复制,一般是4KB。
引导扇区($Boot) —-> 第0项记录($MFT) —-> 根目录记录(第5项,90H,A0H) —-> 根目录(INDX)小
struct indxHeader // A0H外部缓存文件结构,最大长度一般为4K
{
UCHAR mark[4]; // 标志 "INDX"
UCHAR usnOffset[2]; // 更新序列偏移
UCHAR usnSize[2]; // 更新序列数组大小S
UCHAR LSN[8]; // 日志文件序列号
UCHAR indxVCN[8]; // 本索引缓存在分配索引中的VCN
UCHAR itemOffset[4]; // 第一项索引的偏移(从这里开始计算)
UCAHR itemSize[4]; // 索引项实际大小(B)
UCHAR itemAlloc[4]; // 索引项分配大小(B)(不包括头部) 略小于4K
UCHAR isNode; // 是结点置1,表示有子节点
UCHAR noUse[3];
//UCHAR USN[2S]; // 更新序列号和数组
};
在文件头之后就是目录项了,项的结构就是在上面90H的介绍里定义的indexItem,每一个项代表一个文件或目录的MFT项,通过项的 MFT 记录号可以计算出MFT项的磁盘地址,它等于$MFT 的偏移地址 + 编号*0x400,以此可以找到该索引项对应的文件或子目录的MFT项。
上面说了,一个文件的MFT项的地址等于$MFT的地址+MFT编号*0x400,如果目录中的对应项删除了,那么可以从MFT的首部开始检索,因为MFT一般是连续的,而一个MFT项的大小又是固定的,一项项读取,找到各自的0x30属性,解析出文件名,进行比较 (MFT中有一些空白区域需要跳过)。
一般在文件名的前一个字节是文件名的命名空间,不管是INDX文件中,还是0x30属性中。
- 0x00 —- POSI ,最大的命名空间,大小写敏感,支持除 ‘\0’ 和 ‘/’ 所有Unicode字符,最大程度255个字符;
- 0x01 —- Win32,是POSI的子集,不支持字符:* / < > | \ : ? ,不能用句点或空格结束;
- 0x02 —- DOS , 是Win32的子集,字符必须比空格0x20大,文件名1~8个字符,然后句点分割接后缀扩展名1~3个字符;
- 0x03 — DOS&Win32,必须兼容Win32和DOS命名方式
在INDX文件中,经常可以看到含有0x02和0x03或者0x01的两个不同命名空间、相同MFT编号的项,也就是说这两个目录项指向同一个记录,同样的在这个文件的MFT项中也有两个0X30属性,其中一个是0x01或0x03,表示的是完整的文件名;另一个是0x02,DOS命名方式,它是一个短文件名,它在我们命名的基础上,截断 ‘.’ 之前的超出6个字符的所有字符,只剩前6个,之后接上"~1" ,这样正好8个字符,当然后面的句点和扩展名保留。另外,它必须满足DOS命名规则,必须大写,删除禁止使用的字符等等。如果文件名重复了,在 “~1” 基础上递增,"~2","~3"等等。检索比对时,我们自然要使用前者
字符集是字符在计算机上的编码方式,可以看成一种协议,一种约定规则,我们处理一串二进制数所代表的字符时,必须清楚它用的是哪一种编码方式;在windows系统中文件的命名是固定用两个字节表示一个字符,在MFT中可以发现英文文件名字符之间都填充一个 ‘\0’ ,这是宽字符集与变长字符集兼容,在宽字符集中,小于128的字符数值上是等于ASCII码;我们的文件数据一般用的是变长字符集(GB2312等等);为了比较输入的文件名和NTFS中的文件名,我们必须要先转换;两个WinAPI 函数,用于宽字符和变长字符转换
// 函数原型
int WideCharToMultiByte(
UINT CodePage, // code page
DWORD dwFlags, // performance and mapping flags
LPCWSTR lpWideCharStr, // address of wide-character string
int cchWideChar, // number of characters in string
LPSTR lpMultiByteStr, // address of buffer for new string
int cchMultiByte, // size of buffer
LPCSTR lpDefaultChar, // address of default for unmappable
// characters
LPBOOL lpUsedDefaultChar // address of flag set when default
// char. used
);
int MultiByteToWideChar(
UINT CodePage, // code page
DWORD dwFlags, // character-type options
LPCSTR lpMultiByteStr, // address of string to map
int cchMultiByte, // number of bytes in string
LPWSTR lpWideCharStr, // address of wide-character buffer
int cchWideChar // size of buffer
);
//--- WCHAR 定义在tchar.h中 ----
void charTest()
{
TCHAR tc1[16] ; //= _T("后来");
WCHAR tc2[8] = {0x540E, 0x6765, 0, 0, 0, 0, 0, 0};
// memset(tc2, 0, 20);
// MultiByteToWideChar(CP_ACP, 0, tc1, 4, (LPWSTR)tc2, 4);
WideCharToMultiByte(CP_ACP, 0 ,(WCHAR*)tc2, 2, tc1, sizeof(tc1), 0, 0);
cout<<"tc1 "<<tc1<<sizeof(tc1)<<" "<<strlen(tc1)<<endl;
PrintHex(tc1);
cout<<endl;
cout<<"tc2 "<<sizeof(tc2)<<" "<<wcslen((LPWSTR)tc2)<<endl;
PrintHex(tc2);
cout<<endl;
}