Beginning C , Fifth Edition 第9章:函数再探
学习了第8章后,读者就应具备创建和使用函数的基础知识了。本章将以此为基础,介绍函数的使用和操作,尤其是如何通过指针访问函数。也会使用一些更灵活的方法在函数之间通信。 本章的主要内容:
- 函数指针的概念及其用法
- 如何在函数内使用静态变量
- 如何在函数之间共享变量
- 函数如何调用自己,而不陷入无限循环
- 编写一个五子棋游戏(也称为Reversi)
指针对于操作数据和含有数据的变量是一个非常有用的工具。只要一把火钳就可处理所有火热的东西;同样,使用指针也可以操作函数,函数的内存地址存储了函数开始执行的位置(起始地址),存储在函数指针中的内容就是这个地址。
不过,仅有地址还不够。如果函数通过指针来调用,还必须提供变元的类型和个数,以及返回值的类型。编译器不能仅通过函数的地址来推断这些信息。这意味着,声明函数指针比声明数据类型指针复杂一些。指针包含了地址,而且必须定义一个类型;同样,函数指针也包含了地址,也必须定义一个原型。
函数指针的声明看起来有点奇怪,容易混涌,所以下面从一个简单的例子开始:
int (*pfunction) (int);
这是一个函数指针变量的声明,它不指向任何内容-一该语句只定义了指针变量。这个指针的名称是 pfunction,指向一个参数是 int 类型、返回值是 int 类型的函数。而且,这个指针只能指向有这些特征的函数。如果函数接受 float 变元,返回 float 值,就需要声明另一个有这些特征的指针。图 9-1 说明了声明的各个成分。
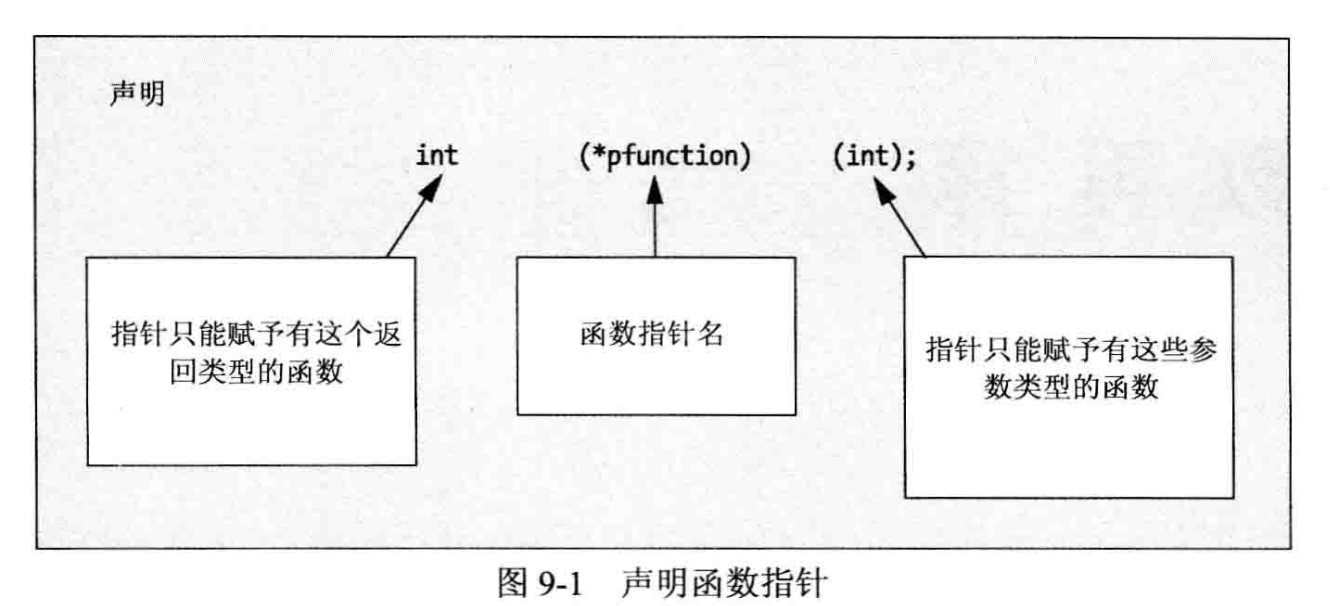
在函数指针的声明中有许多括号。在这个例子中,声明的 *pfunction 部分必须放在括号中。如果省略了括号,就变成 pfunction()函数的声明了,这个函数返回一个指向 int 的值,这可不是我们希望的结果。第二对括号包含参数列表,这与标准函数声明相同。函数指针只能指向特定的函数,该函数有特定的返回类型、特定的参数个数和特定类型的参数。函数名称可以随意,与其他指针变量一样。
假定定义如下函数原型:
int sum (int a, int b); // Calculates a+b
这个函数有两个 int 类型的参数,返回值的类型是 int,所以可以把它的地址存储在声明如下的函数指针中:
int (*pfun)(int, int)= sum;
这条语句声明了一个函数指针 pfun,它存储函数的地址,该函数有两个 int 类型的参数,返回值的类型是 int。该语句还用 sum()函数的地址初始化 pfun。要提供初始值,只需要使用有所需原型的函数名。
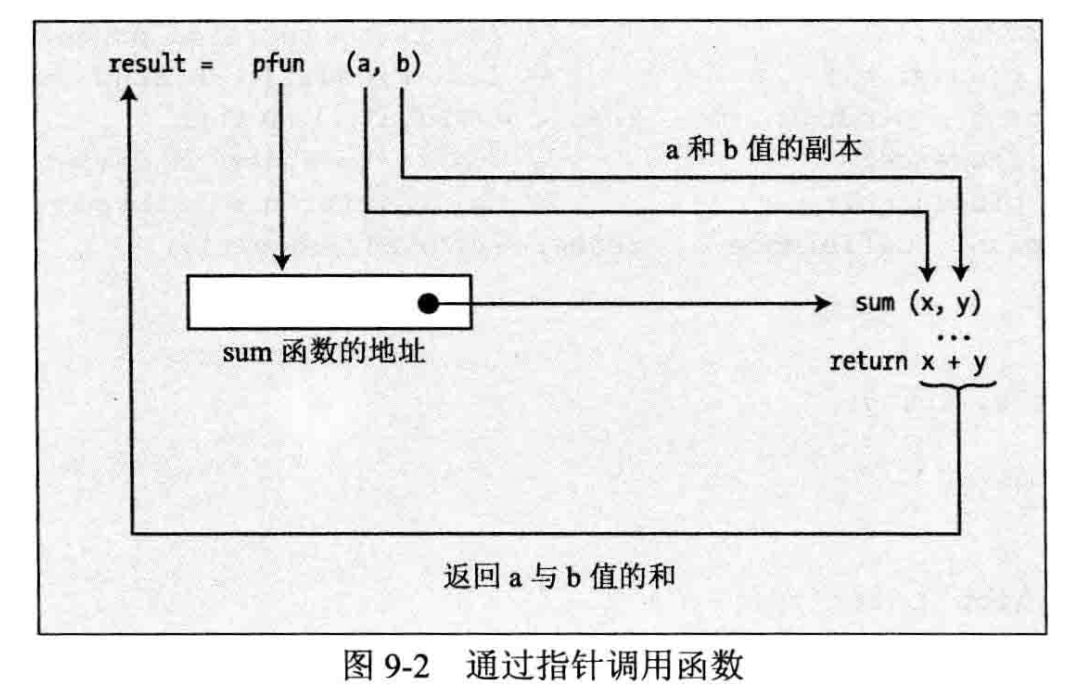
现在可以通过函数指针调用sum()函数:
int result = pfun (45, 55);
这条语句通过 pfun 指针调用变元值为 45 和 55 的 sum()函数,将 sum()的返回值用作 result 变量的初始值,因此 result 是100。注意,像使用函数名那样使用函数指针名调用该指针指向的函数,不需要取消引用运算符。
假定定义了有如下原型的另一个函数:
int product (int a, int b); // Calculates a*b
就可以使用下面的语句在 pfun 中存储 product() 的地址:
pfun = product;
pfun包含 product()的地址,所以可以通过指针调用 product():
int result = pfun (5, 12);
执行了这条语句后,result就包含60。
下面以一个简单的例子来说明函数指针是如何运作的。
#include <stdio.h>
// Function prototypes
int sum(int, int);
int product(int, int);
int difference(int, int);
int main(void) {
int a = 10;
int b = 5;
int result = 0;
int (*pfun)(int, int);
pfun = sum;
result = pfun(a, b);
printf("pfun = sum result = %2d\n", result);
pfun = product;
result = pfun(a, b);
printf("pfun = product result = %2d\n", result);
pfun = difference;
result = pfun(a, b);
printf("pfun = difference result = %2d\n", result);
return 0;
}
int sum(int x, int y) {
return x + y;
}
int product(int x, int y) {
return x * y;
}
int difference(int x, int y) {
return x - y;
}
这个程序的输出结果如下:
pfun = sum result = 15
pfun = product result = 50
pfun = difference result = 5
在此将指针名当成函数名来使用,后面跟随放在括号中的变元列表。而将函数指针变量名当做原来的函数名,则变元列表必须对应函数头的参数列表,如图9-2所示。
函数指针和一般的变量是一样的,所以可创建函数指针的数组。要声明函数指针数组,只需要将数组的大小放在函数指针数组名之后。例如:
int (*pfunctions[10])(int)
这条语句声明了一个包含 10个元素的 pfunctions 数组。这个数组里的每个元素都能存储一个函数的地址,该函数有两个int类型的参数,返回类型是int。下面看一个实例。
#include <stdio.h>
// Function prototypes
int sum(int, int);
int product(int, int);
int difference(int, int);
int main(void) {
int a = 10;
int b = 5;
int result = 0;
int (*pfun[3])(int, int);
pfun[0] = sum;
pfun[1] = product;
pfun[2] = difference;
for(int i = 0;i<3;i++){
result = pfun[i](a,b);
printf("pfun result = %2d\n", result);
}
return 0;
}
int sum(int x, int y) {
return x + y;
}
int product(int x, int y) {
return x * y;
}
int difference(int x, int y) {
return x - y;
}
这类似于前面对一个指针变量的声明,只是指针名称后面多了放在方括号中的数组大小。如果需要的是二维数组,就应有两对方括号,如同声明一般的数组类型一样。参数列表仍然要放在括号内,这与单个指针的声明相同。另外,和一般的数组一样,函数指针数组的所有元素都是相同的类型,都只能接受指定的变量列表。因此在此例中,这些指针都只能指向带两个int参数、返回int值的函数。
给数组中的指针赋值时,语句和一般的数组元素相同:
pfun[0] = sum;
除了等号右侧的函数名称之外,这就是一个正常的数据数组,其用法也完全相同。可以在声明中初始化指针数组的所有元素:
int (*pfun [3]) (int, int) = ( sum, product, difference );
这条语句初始化了3个元素,所以不再需要执行初始化的赋值语句。事实上,也可以去掉数组的大小,由初始化列表确定数组的大小:
int (*pfun []) (int, int) = ( sum, product, difference );
大括号内的初始值个数确定了数组中的元素数目。因此,函数指针数组的初始化列表与其他数组的初始化列表的作用相同。
这行语句说明,可以通过指针将函数调用合并到表达式中,这和使用一般函数调用的方式相同。这里通过指针调用两个函数,将它们的结果用作通过指针调用的第三个函数的变元。pfun数组元素依次对应函数sum()、product()和difference(),因此这行语句相当于下面的语句:
也可以将函数指针作为变元来传递,这样就可以根据指针所指向的函数而调用不同的函数了。
修改上一个例子,将函数指针作为变元传入函数:
#include <stdio.h>
// Function prototypes
int sum(int, int);
int product(int, int);
int difference(int, int);
int any_function (int (*pfun) (int, int), int x, int y);
int main(void) {
int a = 10;
int b = 5;
int result = 0;
int (*pf)(int, int) = sum;
result = any_function(pf, a, b);
printf("pfun result = %2d\n", result);
result = any_function(product, a, b);
printf("pfun result = %2d\n", result);
result = any_function(difference, a, b);
printf("pfun result = %2d\n", result);
return 0;
}
int any_function(int (*pfun) (int, int), int x, int y) {
return pfun(x,y);
}
int sum(int x, int y) {
return x + y;
}
int product(int x, int y) {
return x * y;
}
int difference(int x, int y) {
return x - y;
}
将函数指针作为变元的函数是 any_function(),它的函数原型如下:
int any_function (int (*pfun) (int, int), int x, int y);
any_function() 函数有3个参数,第一个参数是一个函数指针,它指向的函数接受两个整数参数并返回整数。any_function() 函数的后两个参数都是整数,在调用第一个参数指定的函数时使用。any_function() 函数返回一个整数,而这个整数是调用第一个变元指定的函数得到的。
在 any_function()函数的定义里,指针变元指定的函数在 return 语句中调用:
int any_function(int (*pfun) (int, int), int x, int y) {
return pfun(x,y);
}
这个定义使用了指针名称 pfun ,后跟的另外两个参数用作被调用函数的变元。pfun的值和另外两个参数x和y的值都来自于 main()。
注意在 main()中声明的函数指针 pf 是如何初始化的:
int (*pf)(int, int) = sum;// Pointer to function
将函数 sum()的名称作为初始化值放在等号的后面,如前所述,只要将函数名作为初始化值,就可以将函数指针初始化为指定函数的地址。
any_function()的第一个调用给any_function()传递了指针pf、变量a及b的值:
result = any_function(pf, a, b);
指针 pf 和平常一样用作变元,any_function()返回的值存储到变量 result 中。pf的初始值是 sum()函数的地址,所以在 any_function()内调用了 sum()函数,因此返回值是 a 与 b 的和。
将程序分解成函数,不仅简化了开发程序的过程,还增强了程序语言解决问题的能力。设计优良的函数常常可以重用,使新应用程序的开发变得更快、更简单。标准库就证明了可重用函数的威力。函数中变量的属性以及 C 语言在声明变量时提供的一些额外功能进一步增强了程序语言的力量。下面介绍函数中的变量。
前面使用的所有变量在执行到定义它的块尾时就超出了作用域,它们在栈上分配的内存会被释放,以供另一个函数使用。这些变量称为自动变量,因为它们是在声明时自动创建的,在程序退出声明它的块后自动销毁。这是一种非常高效的过程,因为只要正在执行的语句在声明变量的函数内,函数中包含数据的内存就会一直保存该数据。
然而在某些情况下,要求在退出一个函数调用后,该调用中的数据可以在程序的其他函数中使用。例如保留函数中的某种计数器,如函数的调用次数或输出行数。这使用自动变量是做不到的。
不过,C语言提供了静态变量,可以达到这个目的。例如用下面的语句声明一个静态变量count:
static int count = 0;
上述语句中的static是C的一个关键字,该语句声明的变量和自动变量有两点不同。第一,虽然它在函数的作用域内定义,但当执行退出该函数后,这个静态变量不会销毁。第二,自动变量每次进入作用域时,都会初始化一次,但是声明为static的变量只在程序开始时初始化一次。静态变量只能在包含其声明的函数中可见,但它是一个全局变量,因此可以用全局变量的方式使用它。
注意:
可以在函数内创建任何类型的静态变量。
下面这个简单的例子演示了静态变量的用法:
#include "stdio.h"
void test1(void);
void test2(void);
int main(void) {
for (int i = 0; i < 5; ++i) {
test1();
test2();
printf("\n");
}
return 0;
}
void test1(void) {
int count = 0;
printf("test1 count = %d\n", ++count);
}
void test2(void) {
static int count = 0;
printf("test2 count = %d\n", ++count);
}
程序的输出结果如下:
test1 count = 1
test2 count = 1
test1 count = 1
test2 count = 2
test1 count = 1
test2 count = 3
test1 count = 1
test2 count = 4
test1 count = 1
test2 count = 5
可以看出,这两个 count 变量是完全不同的,其值的变化清楚地说明了它们是相互独立的。静态变量 count 在函数 test2()内声明,如下所示:
static int count = 0;
可以给这个变量指定初始值,但这里将它初始化为0,因为将它声明为静态变量。
注意:
所有的静态变量都会初始化为0,除非将它们初始化为其他值。
静态变量 count 用于计算函数的调用次数。当程序开始执行时初始化它,程序退出函数后,它的当前值仍然保留。该变量没有在函数的后续调用中重新初始化。由于该变量声明为static,因此编译器只将它初始化一次。初始化操作是在程序开始之前进行的,所以总是可以确保静态变量在使用时初始化。
自动变量 count 在函数 test1() 内的声明如下所示:
int count = 0;
这是自动变量,所以它默认不会在程序开始执行时初始化。如果不给它指定初始值,它将会含有一个垃圾值。这个变量会在每次执行函数时初始化为0,在每次退出 test1()后删除,因此它永远不会大于1。
只要程序开始执行,静态变量就一直存在,但是它只能在声明它的范围内可见,不能在该作用域的外部引用。
也可以在所有的函数之间共享变量。常量在程序文件的开头声明,所以常量位于组成程序的所有函数的外部)。同样,也可以采用这种方式声明变量,这种变量称为全局变量,因为它们可以在任意位置访问。全局变量的声明方式和一般变量相同,但声明它的位置非常重要,这个位置确定了变量是否为全局变量。
修改前一个例子,在函数之间共享count变量。
#include "stdio.h"
int count = 0;
void test1(void);
void test2(void);
int main(void) {
int count = 0;
for (int i = 0; count < 5; ++count) {
test1();
test2();
printf("\n");
}
return 0;
}
void test1(void) {
printf("test1 count = %d\n", ++count);
}
void test2(void) {
static int count;
printf("test2 count = %d\n", ++count);
}
在这个例子中,有3个不同的 count 变量。第一个是全局变量 count ,它在文件的开头声明:
#include "stdio.h"
int count = 0;
这不是静态变量(但也可以把它声明成静态变量),而是全局变量,所以如果没有初始化它,它就默认为0。从声明该全局变量到程序结束的任何函数中都可以访问它。
第二个 count 是自动变量,在 main() 函数中声明:
int count = 0;
它和全局变量同名,所以在 main() 函数中不能访问全局变量 count.在 main()函数中使用的 count 都是在 main()函数体中声明的自动变量。本地变量隐藏了全局变量。
第三个 count 是静态变量,在函数 test2()里声明:
static int count;
这是一个静态变量,所以默认初始化为 0。这个变量也隐藏了同名的全局变量,所以在 test2()内只能访问静态变量 count。
函数 test1() 使用的是全局变量 count。函数 main()和 test2()使用的是 count的本地版本,因为本地声明隐藏了同名的全局变量。
显然,main()内的 count 变量从 0 递增到 4,因为调用了 5 次 test1()和 test2()。在 test1()及 test2()内, count变量是不同的,否则程序就不会输出 1~5 的值。
删除 test2()内对静态变量 count 的声明,可以进一步证实这个事实。这会使 test1()和 test2()共享全局变量 count,显示出的值会变成 1~10。如果将 test2()内的 count 变量改成已初始化的自动变量,如下面的语句所示:
int count = 0;
test1()会输出 1~5 ,而 test2()的输出始终是 1 ,这是因为该变量现在是自动变量,每次执行函数时都会重新初始化。
全局变量可以取代函数变元及返回值。完全取代自动变量似乎很吸引人,但应少使用全局变量,全局变量可以简化并缩短某些程序,但过度使用会使程序很难理解,且容易出错。主要原因是很容易修改全局变量,却忘记它对整个程序带来的后果。程序越大,避免错误引用全局变量的难度就越大。而本地变量可以有效地隔离各个函数,避免这些函数的活动互相干扰。删除程序 9.5 中 main() 的本地变量 count ,看看输出结果会如何。
注意:
在 C 语言中,最好不要给本地变量和全局变量使用相同的名称。这不但没有好处,反而有坏处,如上面的例子所示。
函数调用自己称为递归。递归在程序设计中不常见,所以本节仅介绍概念。不过在某些情况下,这是一个效率很高的技巧,可以显著简化解决特定问题所需的代码。递归也有几个坏处,但这里也不涉及。
显然,函数调用自己时,一个直接的问题是如何停止递归过程。下面的函数示例就陷入了一个无限循环:
void Looper (void){
printf ("Looper function called. \n");
Looper ();
}
调用这个函数会输出无数行结果,因为在执行printfO调用后,函数会调用它自己。代码中没有停止该过程的机制。这就类似于一个无限循环问题,解决方法也很类似:个调用自己的函数必须包含停止处理的方式,下面说明这个方式。
递归的主要用途是解决复杂的问题,所以很难用简单的例子说明其工作原理。因此,这里使用标准证明方式:计算整数阶乘。所谓整数阶乘,就是从1到该整数的所有整数之积。下面是相关代码:
#include "stdio.h"
# define __STDC_WANT_LIB_EXT1__ 1
unsigned long long factorial(unsigned long long);
int main(void) {
unsigned long long number = 0LL;
printf("Enter an integer value:");
scanf_s("%llu", &number);
printf("The factorial of %llu is %llu\n", number, factorial(number));
return 0;
}
unsigned long long factorial(unsigned long long n) {
if (n < 2LL)
return n;
return n * factorial(n - 1LL);
}
程序的输出结果如下:
Enter an integer value:15
The factorial of 15 is 1307674368000
在标准库中,某些函数的变元数是可变的,例如函数 printf()和 scanf()。有时需要这么做,所以标准库<stdarg.h>提供了编写这种函数的例程。
编写参数个数可变的函数时,第一个明显的问题是如何指定它的原型。假设要创建一个函数,计算两个或多个 double值的平均值。显然,计算少于两个数的平均值是没有意义的。它的原型可以这么编写:
double average (double vl, double v2,...);
第二个参数类型后的 3 个点(省略号)表示,在前两个固定的变元后面,可以有数量可变的变元。至少要有一个固定的变元,其他内容和一般的函数原型一样,前两个变元是double类型,返回的结果也是double类型。
变元个数可变的第二个问题是,在编写函数时如何引用变元?我们不知道有多少个变元,所以不可能给它们指定名称。唯一的方法是通过指针间接地指定变元。<stdarg.h>头文件为此提供了通常实现为宏的例程,宏的外观和操作都类似于函数,所以将它们作为函数来讨论。要实现变元个数可变的函数,必须同时使用3个宏: va_start()、va_arg()、va_end()。第一个宏的形式如下:
void va_start (va_list parg, last_fixed_arg);
这个宏的名称来源于 variable argument start。这个函数接受两个变元: va_list 类型的指针 parg 和为函数指定的最后一个固定参数的名称。va_list 类型也在<stdarg.h>头文件中定义,用于存储支持可变参数列表的例程所需的信息。
以 average() 函数为例,可以将该函数编写成:
double average (double vl, double v2, ...){
va_list parg; // Pointer for variable argument list
// More code to go here...
va_start ( parg, v2);
// More code to go here...
}
首先,声明一个 va_list 类型的变量 parg。然后,用 parg 作为第一个变元,指定最后一个固定参数 v2 作为第二个变元,调用 va_start()。调用 va_start()的结果是将变量 parg 设定为指向传送给函数的第一个可变变元。此时并不知道这个值的类型,标准库对此也无能为力。但必须确定每一个可变变元的类型,例如假设所有的可变变元都是同一种特定的类型,或从固定变元包含的信息推断每个变元的类型。
average() 函数处理 double 类型的变元,所以确定可变变元的类型不成问题。现在必须知道如何访问每个可变变元的值,因此下面完成 average()函数:
double average(double vl, double v2, ...) {
va_list parg; // Pointer for variable argument list
double sum = vl + v2;
double value = 0.0;
int count = 2;
va_start (parg, v2); // Initialize argument pointer
while ((value = va_arg (parg, double)) != 0.0) {
sum += value;
++count;
}
va_end (parg); // End variable argument process
return sum / count;
}
在声明 parg 后,将变量 sum 声明为 double 类型,同时用前两个固定变元 v1 和 v2 的和来初始化 sum。所有变元值的和都会累加到 sum 中,所以下一个变量 value 声明成 double ,用于存储获得的每个可变变元的值。然后声明计数器 count ,用来存储变元的数目,并将该计数器初始化为 2,因为至少有两个固定变元。在调用 va_start() 初始化 parg 后,在下面的 while 循环内执行大部分的操作:
while ((value = va_arg (parg, double)) != 0.0)
循环条件调用了<stdarg.h>头文件中的另一个函数 va_arg()。 va_arg()的第一个变元是通过调用 va_start()初始化的变量 parg,第二个变元是期望确定的变元类型的说明。 va_arg()函数会返回 parg 指定的当前变元值,并将它存储到 value 中。同时会更新 parg 指针,使之根据调用中指定的类型,指向列表中的下一个变元。必须有某种方式来确定可变变元的类型,因为如果指定的类型不正确,就不能正确得到下一个变元。在这个例子中编写函数时,假设所有的变元都是 double 类型。另一个假设是除了最后一个变元外,其他变元都是非零值。这反映在循环继续条件中,即 value 不等于 0 。在循环中,在 sum 中累计总和,并递增 count.
变元值等于 0 时,就结束循环,执行下一行语句:
va_end (parg);
调用va_end()函数,处理该过程的剩余工作。它将parg重置为指向NULL。如果省掉这个调用,程序就不会正常工作。整理完成后,就可以用下面的语句返回需要的结果了:
return sum / count;
编写完函数 average() 后,最好用一个小程序确保它可以正常工作:
#include "stdio.h"
#include "stdarg.h"
double average(double vl, double v2, ...);
int main(void) {
double v1 = 10.5, v2 = 2.5;
int num1 = 6, num2 = 5;
long num3 = 12L, num4 = 20L;
printf("Average = %.2lf\n", average(v1, 3.5, v2, 4.5, 0.0));
printf("Average = %.2lf\n", average(1.0, 2.0, 0.0));
printf("Average = %.2lf\n", average((double) num2, v2, (double) num1, (double) num4, (double) num3, 0.0));
return 0;
}
double average(double vl, double v2, ...) {
va_list parg; // Pointer for variable argument list
double sum = vl + v2;
double value = 0.0;
int count = 2;
va_start (parg, v2); // Initialize argument pointer
while ((value = va_arg (parg, double)) != 0.0) {
sum += value;
++count;
}
va_end (parg); // End variable argument process
return sum / count;
}
编译并运行程序,输出如下:
Average = 5.25
Average = 1.50
Average = 9.10
这是用不同数目的变元调用 3 次 average() 的结果。可变的变量必须转换成 double 类型,因为这是函数 average() 假设的变元类型。可以用任何数目的变元调用 average() 函数,但最后一个变元必须是 0.0。
printf()如何处理混合类型? printf()的第一个变元是带有格式说明符的控制字符串,它提供的信息确定了其后变元的类型和个数。第一个变元后面的变元个数必须匹配控制字符串中格式说明符的数目,这些变元的类型也必须符合对应的格式说明符隐含的类型。如果为要输出的变量指定了错误的类型,输出的结果就不正确。
有时需要多次处理可变的变元列表。<stdarg.h>头文件为此定义了一个复制已有 va_list 的例程。假定在函数中使用 va_start() 创建并初始化了一个 va_list 对象 parg,现在要复制 parg:
va_list parg_copy;
va_copy (parg_copy, parg) ;
第一条语句创建了一个新的 va_list 变量 parg_copy,下一条语句将 parg 的内容复制到 parg_copy 中。接着可以独立地处理 parg 和 parg_copy,使用 va_arg()和 va_end() 提取变元值。
注意, copy()例程复制 va_list 对象时,不需要考虑它所处的状态。所以,如果用 parg 执行va_arg(),从列表中提取变元值,之后执行 copy() 例程, parg_copy 的状态就与已经提取出来的一些变元值相同。另外注意,在对 parg_copy 执行pa_end()之前,不能将 va_list 对象 parg_copy 用作另一个复制过程的目标。
以下是编写变元数目可变的函数的基本规则:
- 在变元数目可变的函数中,至少要有一个固定变元。
- 必须调用 va_start()初始化函数中可变变元列表指针的值。变元指针的类型必须声明为 va_list类型。
- 必须有确定每个变元的类型的机制。可以假设默认的类型,或用一个参数来指定变元的类型。例如,在 average()函数中,可以有另一个固定的变元,它的值为 0 时表示变元的类型是 double;它的值为 1 时表示变元的类型是 long。如果在 va_arg() 调用中指定的变元类型不对应调用函数时指定的变元值,函数就不能正常工作。
- 必须有确定何时终止变元列表的方法。例如,在可变的变元列表中,最后一个变元有固定的值,称为“哨兵”值,可以检测它,因为它不同于其他变元的值。或者,在第一个变元中包含变元的个数或变元列表中的可变变元个数。
- va_arg()的第二个变元指定了变元值的类型,这个指针类型可以在类型名的后面加上*来指定。最好检查一下编译器的文档说明,了解其他限制。
- 在退出变元数目可变的函数前,必须调用va_end()。否则,函数将不会正常运作。
可以试着修改程序 9.7,更好地了解这个过程。在 average()函数中输出一些信息,看看改变了某些数据后会发生什么。例如,可以在 average()函数的循环中显示 value 和 count,再修改 main(),使用非 double 类型的变元,或调用最后一个变元不是 0.0 的函数。
main()函数是程序执行的起点。这个函数有一个参数列表,在命令行中执行程序时,可以给它传递变元。main(函数可以有两个参数,也可以没有参数。
main()函数有参数时,第一个参数的类型是 int,表示在命令行中执行 main()函数的参数个数,包含程序名在内。第二个参数是一个字符串指针数组。因此,如果在语句行中,在程序名称的后面添加两个变元,main()函数的第一个变元值就是 3,第二个参数是一个包含 3 个指针的数组,第一个指针指向程序的名称,第二和第三个指针指向在命令行上输入的两个变元。
#include "stdio.h"
int main(int argc, char *argv[]) {
printf("Program name: %s\n", argv[0]);
for (int i = 1; i < argc; ++i)
printf("Argument %d: %s\n", i, argv[i]);
return 0;
}
argc 的值至少是1,因为执行程序时,必须输入程序名称。argv[0]是程序名称,argv 数组中的后续元素是在命令行下输入的变元。上述程序在 for 循环中依序输出这些变元。
这个程序的源文件是 D:\Projects\GitHubProjects\USFM\9\9.5\cmake-build-debug\main.c,所以输入如下命令来执行它:
first second_arg "Third is this"
注意,使用双引号包含有空格的变元。这是因为空格一般被看做分隔符。可以将变元放在双引号中,确保将它当作一个变元。
上述命令会创建下面的输出:
D:\Projects\GitHubProjects\USFM\9\9.5\cmake-build-debug\main.exe first second_arg "Third is this"
Program name: D:\Projects\GitHubProjects\USFM\9\9.5\cmake-build-debug\main.exe
Argument 1: first
Argument 2: second_arg
Argument 3: Third is this
将最后一个变元放在双引号中,确保将它看做一个变元,而不是 3 个变元。
所有命令行变元都以字符串读入,如果在命令行上输入数值,就需要把包含数值的字符串转换成适当的数值类型。为此可以使用表9-1中的函数,这些函数在<stdlib.h>头文件中声明。
表9-1 将字符串转换为数值的函数
| 函数 | 说明 |
|---|---|
| atof() | 将作为变元传送的字符串转换为 double 类型 |
| atoi() | 将作为变元传送的字符串转换为 int 类型 |
| atol() | 将作为变元传送的字符串转换为 long 类型 |
| atoll() | 将作为变元传送的字符串转换为 long long 类型 |
例如,如果需要将一个命令行变元用作整数,可以用下面的方式处理:
int arg_value = 0;
if (argc > 1)
arg_value = atoi(argv [1]);
else{
printf ("Command line argument missing. ");
return 1;
}
注意检查变元的个数,在处理命令行变元前,先检查变元的数目是很重要的,因为很容易忘记输入变元。
上一章的程序 8.4 有多个实例,说明在 main()调用的函数中,可能需要结束程序的执行。在 main()中,可以返回以结束程序。但在其他函数中不会使用这个技术。在其他函数中结束程序可以是正常或不正常程序结束。函数确定计算结束是因为没有更多的数据要处理,或者用户输入的数据表示程序应结束。这些情形会导致程序正常结束。一般情况下,需要在一个函数中不正常地结束程序时,通常是因为在函数中检测到某个灾难性的状态,例如数据中某个严重的错误使程序不能继续执行;或者发生了大多数情况下不会发生的外部故障,例如找不到磁盘文件,或者在读取文件时检测到错误。
stdlib.h 头文件提供的几个函数可以用于终止程序的执行。stdlib.h 头文件还提供了一些函数,标识出在程序正常结束时要调用的一个或多个自定义函数。这类函数可能没有参数,且把返回类型指定为void。当然,应通过函数指针标识要在终止程序时调用的函数。
调用 abort() 函数会不正常地结束程序。它不需要参数,当然也没有返回值。希望结束程序时,可以调用它:
abort();
该函数会清空输出缓冲区,关闭打开的流,但它是否这么做取决于实现代码。
调用 exit() 函数会正常结束程序。该函数需要一个 int 类型的参数,它表示程序结束时的状态。该参数可以是 0 或者表示成功结束的 EXIT_SUCCESS,它会返回给主机环境。例如:
exit(EXIT_SUCCESS);
如果变元是 EXIT_FAILURE,就把表示终止不成功的消息返回给主机环境。无论如何, exit()都会清空所有输出缓冲区,把它们包含的数据写入目的地,再关闭所有打开的流,之后把控制权返回给主机环境。返回给主机环境的值由实现代码确定。注意调用 exit()会正常终止程序,无论变元的值是什么。调用 atexit(),可以注册由 exit()调用的自定义函数。
调用 atexit()会标识应用程序终止时要执行的函数。下面是其用法:
void CleanUp (void); // Prototype of function to be called on normal exit
...
if (atexit(CleanUp))
printf("Registration of function failed! \n");
把要调用的函数名作为变元传递给 atexit(),如果注册成功,就返回 0,否则返回非 0 值。调用几次 atexit(),就可以注册几个函数,必须给函数提供遵循 C 标准的实现代码,且注册的函数最多为 32 个。把几个函数注册为调用 exit()时执行,它们就在程序终止时以注册顺序的倒序调用。即调用 atexit()注册的最后一个函数最先执行。
_Exit()函数的作用与 exit()相同,它也会正常终止程序,并把变元值返回给主机环境。区别是它无法影响程序终止时调用 _Exit()函数的结果,因为它不调用任何已注册的函数。调用 _Exit()的方法如下:
_Exit(1);
调用 quick_exit() 会正常终止程序,再调用 _Exit() 把控制权返回给主机环境。 quick_exit()的变元是一个 int 类型的状态码,该函数在调用 _Exit() 时传递该变元。在调用 _Exit() 之前, quick_exit()会调用通过 at_quick_exit()函数调用注册的函数。下面把函数注册为由quick_exit()调用:
void CloseFiles (void) ;
void CloseCommunicationsLinks (void);
...
at_quick_exit (CloseCommunicationsLinks);
at_quick_exit (CloseFiles);
最后两个语句把函数注册为由 quick_exit()调用,于是先调用 CloseFiles(),再调用CloseCommunicationLinks()。
quick_exit()函数提供了与 exit()平行的程序终止机制。注册为由 exit()和 quick_exit()调用的函数完全相互独立。通过调用 atexit()注册的函数不由 quick_exit()调用,用at_quick_exit()注册的函数也不由 exit()调用。
有 3 个工具可以使编译器生成性能更佳的代码。其中一个工具与短函数调用的编译方式相关,另一个工具涉及指针的使用。但这些工具不能保证其效果,而是取决于编译器的实现方式。第三个工具用于永远不返回的函数。这里先探讨短函数。
C语言的功能结构要求将程序分解为许多函数,函数有时可以非常短。短函数的每次调用可以用实现该函数功能的内联代码替代,以提高执行性能。这意味着不需要给函数传递值或返回一个值。要让编译器采用这种技术,可以把短函数指定为 inline,下面是一个例子:
inline double bmi(double kg_wt, double m_height) {
return kg_wt / (m_height * m_height);
}
这个函数根据成人的体重(Kg)及身高(m)计算其体质指数。这个操作可以定义为一个函数,也可以使用调用的内联实现方式,因为其代码非常简单。要采用后一种方式,需要在函数头中使用 inline 关键字来指定。但一般不保证编译器能识别声明为 inline 的函数,因为该关键字对于编译器来说只是一个提示。
专业的 C 编译器可以优化对象代码的性能,这涉及到改变在代码中为操作指定的计算顺序。为了优化代码,编译器必须确保操作的这种重新排序不影响计算的结果,并用指针指出这方面的错误。为了优化涉及指针的代码,编译器必须能确定指针是没有别名的一一换言之,每个指针引用的数据项都没有在给定范围内以其他方式引用。关键字 restrict 就可以告诉编译器,何时出现这种情况,并允许应用代码优化功能。下面是一个在<string.h>中声明的函数示例:
errno_t strcpy_s (char * restrict s1, rsize_t slmax, const char * restrict s2){
// Implementation of the function to copy s2 to s1
}
这个函数将 s2 复制到 s1 中。关键字 restrict 应用于两个指针参数,表示在函数体中,s1和 s2 引用的字符串仅通过这两个指针引用,所以编译器可以优化为该函数生成的代码。关键字 restrict 仅将信息告知编译器,但不保证进行优化。当然,如果在条件不具备的代码上应用了关键字 restrict ,代码就会生成不正确的结果。在大多数情况下,不需要使用关键字 restrict,只有代码进行大量计算,进行代码优化才有显著的效果,而这还取决于编译器。
有时,实现的函数永远都不返回。例如,可能定义一个函数,在程序正常终止时调用。这种函数不会返回,因为控制权会像通常那样返回给调用者,此时,可以告诉编译器,该函数不返回:
_Noreturn void EndAll (void){
// Tidy up open files...
exit (EXIT SUCCESS) ;
}
_Noreturn 限定符告诉编译器,这个函数不返回给其调用函数。因为该函数不返回,所以唯一可用的返回类型是 void。知道一个函数永远都不返回,编译器就可以省略把控制权返回到调用点所需的代码和存储空间。stdnoreturn.h 头文件定义了宏 noreturn,它扩展为_Noreturn,所以只要在源文件中包含这个头文件,就可以使用 noreturn。
到此函数已经介绍完毕,我们的 C 语言学习之旅也已过半,一些不太复杂的问题应该都可以解决。接下来的这个程序将实际用到目前学过的各种 C 元素。
现在要解决的问题是编写一个游戏。选择编写游戏程序有几个理由。首先,游戏比其他类型的程序复杂,即使是比较简单的游戏程序。其次,游戏比较有趣!
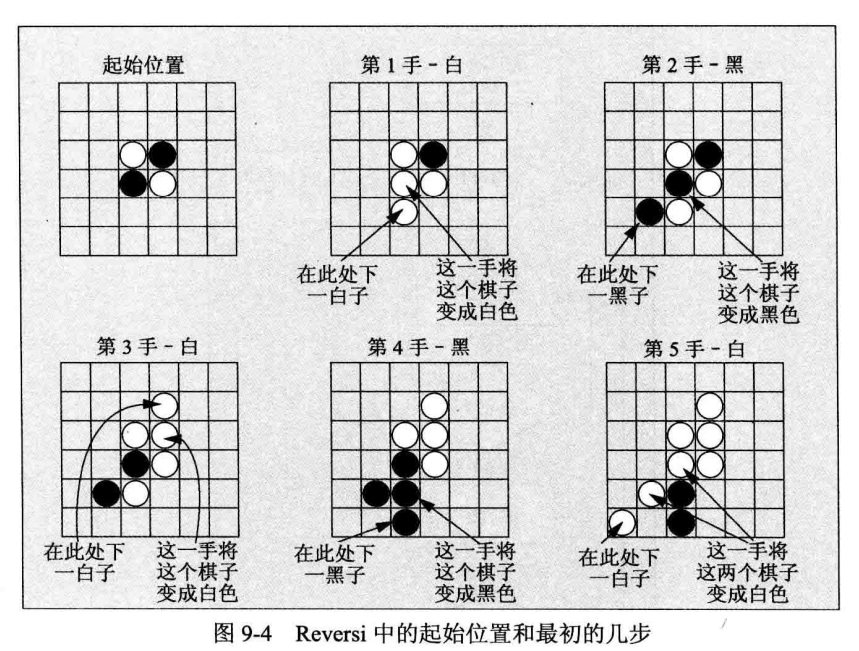
这个游戏与五子棋或 Microsoft Windows 3.0 的 Reversi 有相同的性质。这个游戏要两位玩家在棋盘上轮流放置不同颜色的棋子,一位玩家使用黑子,另一位玩家使用白子。棋盘是一个偶数边的正方形,图 9-4 显示了从开始位置到连续下五子的过程。
只能将一个棋子放在对手的棋子旁,使对手在对角线、水平线或垂直线上的棋子被自己的棋子包围住,这样对手的棋子就变成自己的棋子了;游戏结束时,棋子多的玩家就获胜。如果所有的方格都放置了棋子,游戏就结束;或者没有玩家在放下棋子后能将对方的棋子变成自己的棋子,这局也算结束。这个游戏可以使用任何大小的棋盘,这里使用 6×6 的棋盘,并使一位玩家和计算机对奕。
这个问题的分析和以前所见的稍有不同。本章介绍的重点是结构化编程,换句话说,就是将一个大问题分解成许多小问题逐一解决,这就是要花这么多时间介绍函数的原因。
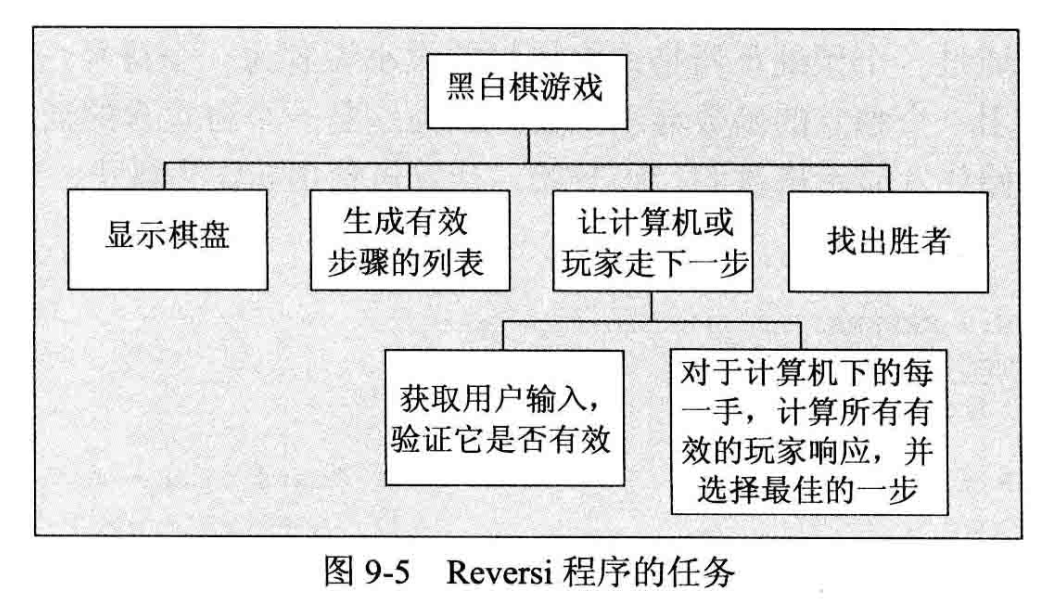
最好先用一张图来进行分析。首先有一个方框,它代表整个程序或 main()函数。下一层是要在 main()函数中直接调用的函数,并说明这些函数的功能。再下一层是这些函数要使用的更小的函数。不必编写函数,只要写出它们必须完成的工作即可。然而这些就是函数要做的工作,所以这是设计程序的一种好方法。图 9-5 显示了程序要执行的任务。
现在可以开始思考操作或函数的执行顺序了。图 9-6 是一个流程图,它不仅描述了这组函数,还描述了这些函数的执行顺序与确定其执行顺序的逻辑。这更精确地说明了程序的运作方式。
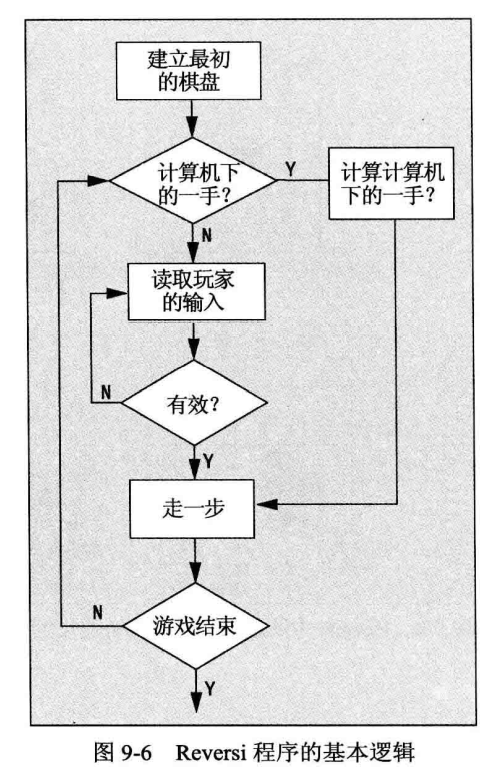
当然,这还没有完成,还必须详细填入许多细节。这种图可以帮助理清程序的逻辑,进而对程序的运作方式进行更详细的定义。
P354
本节列出解决问题的步骤。
首先,建立并显示初始棋盘。为了使游戏程序比较短,使用比较小的棋盘(6×6)。但这里在程序中通过一个预处理器指令将棋盘的大小设置为一个符号,以便在以后改变棋盘的大小。使用一个独立的函数显示棋盘,因为这是一个自包含的活动。
从声明、初始化及显示棋盘的代码开始。计算机使用@作为棋子,玩家使用0作为棋子: