Beginning C , Fifth Edition 第8章:程序的结构
如第 1 章所述,将程序分成适度的自包含单元是开发任一程序的基本方式。当工作很多时,最明智的做法就是把它分成许多便于管理的部分,使每一小部分能很轻松地完成,并确保正确完成整个工作。如果仔细设计各个代码块,就可以在其他程序中重用其中的一些代码块。
C 语言中的一个重要观念是,每个程序都应切割成许多小的函数。前面的所有例子都编写成一个函数main(),还涉及其他函数,因为这些例子还使用各种标准库函数进行输入输出、数学运算和处理字符串。
本章将介绍如何使程序更有效率,利用更多自己的函数更方便地开发程序。
本章的主要内容:
- 数据如何传给函数
- 函数如何返回结果
- 如何定义自己的函数
- 函数原型的概念和使用场合
- 函数使用指针参数的优势
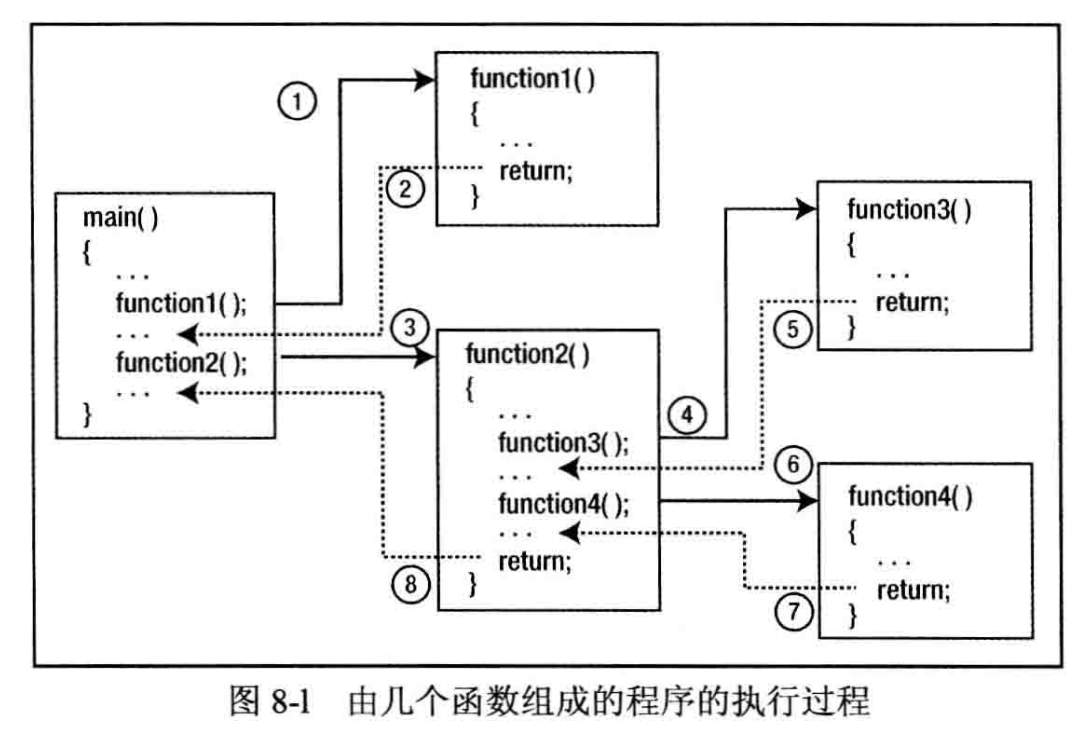
如概述所言,C 程序是由许多函数组成的,其中最重要的就是函数 main(),它是执行的起点。本书介绍库函数 printf() 或 scanf() 时,说明了一个函数可以调用另一个函数,完成特定的工作,在任务完成后调用函数继续执行。不考虑存储在全局变量(参见第9章)中的数据或者可以通过指针参数访问的数据的负面影响,程序中的每个函数都是一个执行特定操作的自包含单元。调用一个函数时,就执行该函数体内的代码,这个函数执行结束后,控制权就回到调用该函数的地方。如图8-1所示为 C 程序由 5 个函数组成时的执行顺序,它并未显示任何语句细节。
这个程序以正常的方式按顺序执行语句,当遇到调用一个函数的语句时,就把参数值传递给函数,从该函数的起始点开始执行,即该函数体的第一条语句。这个函数会一直执行,在遇到 return 语句或到达这个函数体的结束括号时,就返回调用它的那个位置之后执行。
这些组成程序的函数通过函数调用及其 return 语句链接在一起,完成各种工作,以达到程序的目标。图 8-1 中的每个函数在程序中只执行一次。实际上,每个函数可以执行多次,且可以从程序中的多个地方调用。前面的例子中就多次调用函数 printf() 和 scanf()。
在详细了解如何定义自己的函数之前,必须解释变量的一个重要方面,这个方面一直未提及。
在前面所有的例子中,都是在定义 main() 函数体的起始处声明程序的变量。事实上,可以在任何代码块的起始处定义变量。这有什么不同吗?这是绝对不同的。变量只存在于定义它们的块中。它们在声明时创建,在遇到下一个闭括号时就不存在了。
在一个块内的其他块中声明的变量也是这样。在外部块的起始处声明的变量也存在于内部块中。这些变量可以随意访问,只要内部块中没有同名的变量即可。
变量在一个块内声明时创建,在这个块结束时销毁,这种变量称为自动变量,因为它们是自动创建和销毁的。给定变量可以在某个程序代码块中访问和引用,这个程序代码块称为变量的作用域。在作用域内使用变量是没有问题的。但是如果试图在变量的作用域外部引用它,编译程序时就会得到一条错误信息,因为这个变量在它的作用域之外不存在。例如下面的代码:
{
int a = 0; // Create a
// Reference to a is OK here
// Reference to b is an error here - it hasn't been created yet
{
int b= 10; // Create b
// Reference to a and b is OK here
}// b dies here
// Reference to b is an error here - it has been destroyed
// Reference to a is OK here
}// a dies here
对于在一个块内声明的所有变量,在这个块的结束括号之后它们就不再存在。变量 a 可在内外两个块内访问,因为它是在外部块中声明的。变量 b 只能在内部块中访问,因为它是在内部块中声明的。
执行程序时,会创建变量,并给它分配内存。有时,在一个块中声明了自动变量,在这个块结束时,该变量占用的内存就会返回给系统。当然,在执行块内调用的函数时,变量仍存在,只有执行到创建变量的块的尾部时才销毁变量。变量存在的时间称为变量的生存期。
注意:
本代码块声明的变量名称与父代码块声明的变量名称相同,在本代码块使用这个同名变量时,使用的时本代码块声明的变量,而不是父代码块声明的那个同名变量。
在讨论创建函数的细节之前,最后要讨论的是,每个函数体都是一个块(当然,它可能含有其他块)。因此,在一个函数内声明的自动变量是这个函数的本地变量,在其他地方不存在。所以,在一个函数内部声明的变量完全独立于在其他函数或嵌套块内声明的变量。可以在不同的函数内使用相同的变量名称,它们是完全独立的。这的确是一个优点。处理很大的程序时,确保所有变量使用不同的名称是比较困难的。能在不同的函数中使用相同的变量名(如 count)是很方便的。当然,最好避免在不同的函数中使用不必要或易引起误解的相同变量名。应该尽量使用便于理解程序的名称。
本书的程序广泛使用了内置函数,例如 printf() 或 strcpy()。还介绍了在按名称引用内置函数时如何执行它们,如何通过函数名称后括号内的参数给函数传递信息。例如, printf() 函数的第一个参数通常是一个字符串,其后的参数(可能没有)是一系列要显示其值的变量或表达式。
可以通过两种方法接收函数返回的信息。第一种方法是使用函数的一个参数。通过函数的一个参数提供变量的地址,这个函数会修改该变量的值。例如,使用scanf_s()从键盘上读取数据时,输入会存储到一个作为参数提供的地址中。第二种方法是通过返回值接收函数传回的信息。例如对于strlen_s()函数,当调用该函数时,它会返回程序代码作为参数传送给它的字符串的长度。因此,如果在表达式2strlen(str, sizeof(str))中, str是字符串"example",strlen()函数返回的值就是7,接着用值7取代表达式中的函数调用。因此,这个表达式是27。函数会返回一个特定类型的值,所以在能使用该类型变量的任意表达式中,都可以使用函数调用,作为表达式的一部分。所有的程序都必须编写函数 main(),所以我们已经具备函数构成的基本知识。下面详细讨论函数的构成。
创建一个函数时,必须指定函数头作为函数定义的第一行,跟着是这个函数放在括号内的执行代码。函数头后面放在括号内的代码块称为函数体。
- 函数头定义了函数的名称、函数参数(它们指定调用函数时传给函数的值的类型和个数)和函数返回值的类型。
- 函数体包含在调用函数时执行的语句,以及对传给它的参数值执行操作的语句。
函数的一般形式如下所示:
Return_type Function_name(Parameters -separated by commas)
{
// statements...
}
函数体内可以没有语句,但是必须有大括号。如果函数体内没有语句,返回类型必须是 void,此时函数没有任何作用。void 类型表示“不存在任何类型”,所以这里它表示函数没有返回值。没有返回值的函数必须将返回类型指定为 void,而返回类型不是 void 的函数都在函数体中有一个 return 语句,返回一个指定返回类型的值。
没有函数体的函数通常在复杂程序的测试阶段使用。例如,所定义的函数只包含一条 return 语句,返回一个默认值。这允许在执行程序时只用选定的函数执行一些操作,然后逐步增加函数体中的代码,在每个阶段进行测试,直到完成整个工作。
术语“参数”表示函数定义中的一个占位符,指定了调用函数时传送给函数的值的类型。参数包含在函数体内,用来表示函数执行时使用的数据类型和名称。术语“变元”表示调用函数时提供的对应于参数的值。本章后面关于函数的参数部分将详细介绍参数。
注意:
函数体内的语句也可能含有嵌套的语句块,但不能在一个函数体内定义另一个函数。
调用函数的一般形式是:
Function_name(List of Arguments - separated by commas)
使用函数名后跟括号内一连串以逗号分隔的变元,与调用 printf() 和 scanf() 函数一样。函数调用可以显示在一行中,如下所示:
printf("I used to be indecisive but now I'm not so sure.");
像这样调用的函数可以是有返回值的函数。在这个例子中,返回值会被丢弃。返回类型定义为void的函数只能这样调用。有返回值的函数通常会出现在表达式中,例如:
result = 2.0 * sqrt(2.0);
sqrt()函数(在头文件<math.h>中声明)返回的值乘以 2.0,结果存储到变量 result 中。很明显,返回类型为 void 的函数不返回任何值,所以不可能成为表达式的一部分。
1. 函数的命名
在 C 语言中,函数的名称可以是任何合法的名称,但不能是保留字(如int、double和sizeof等),也不能和程序中其他函数的名称相同。注意,不要使用与任何标准库函数相同的名称,以避免混淆。当然,如果使用库函数名,且在源文件中包含该库函数的头文件,程序就不会编译。
区别自己的函数和标准库函数的一个方法是,函数名用一个大写字母开头,但一些程序员觉得这相当受限。函数名以大写字母开头也常常用作 struct 类型名,参见第11章。
合法的函数名与变量名的形式相同:一串字母和数字,第一个必须是字母。与变量名称一样,下划线字符算是一个字母。除此之外,函数的名称可以任意,但是最好能说明函数的作用,且不能太长。有效的函数名称示例如下:
cube_root FindLast findNext Explosion Back2Front
通常,将函数名称(和变量名称)定义为包含多个单词。有3个常见的方法可以采用:
- 在函数名称中用下划线字符分开每个单词。
- 将每个单词的第一个字母大写。
- 将除第一个单词之外的每个单词的第一个字母大写
这 3 种方法都很好,但第3种形式常常用于变量名。采用哪一个取决于程序员,但最好在选择了一种方法后就一直使用它。当然,可以对函数使用一种方法,对变量使用另一种方法。在本书中这3种方法都有使用,阅读完本书后,读者就会对使用哪种方法有自己的看法了。
2. 函数的参数
函数的参数在函数头中定义,是调用函数时必须指定的变元的占位符。函数的参数是一列变量名称和它们的类型,参数之间以逗号分隔。整个参数列表放在函数名称后的括号中。函数也可以没有参数,此时应在括号中放置void。
参数提供了调用函数给被调用函数传递信息的方法。这些参数名对于函数而言是本地的,调用函数时给它们指定的值称为“变元”。然后使用这些参数名在函数体中编写计算操作,当函数执行时,参数使用变元的值。当然,函数也可以在函数体中声明本地定义的自动变量。函数执行完毕后,这些变量就会销毁。最后当计算完成时,如果返回类型不是void,函数将一个适当的值返回给原来的调用语句,并从那一点继续执行。
要把数组作为变元传递给函数,还必须传递一个额外的变元,指定数组的大小。没有这个额外参数,函数就不知道数组中有多少个元素。
调用函数时,要使用函数名称,后跟放在括号中的变元。在调用时指定的变元会取代函数中的参数。因此,函数执行时,会使用为变元提供的值进行计算。调用函数时指定的变元的类型、个数和顺序必须和函数头中指定的参数一致。调用函数和被调用函数之间的关系与传送的信息如图8-2所示。
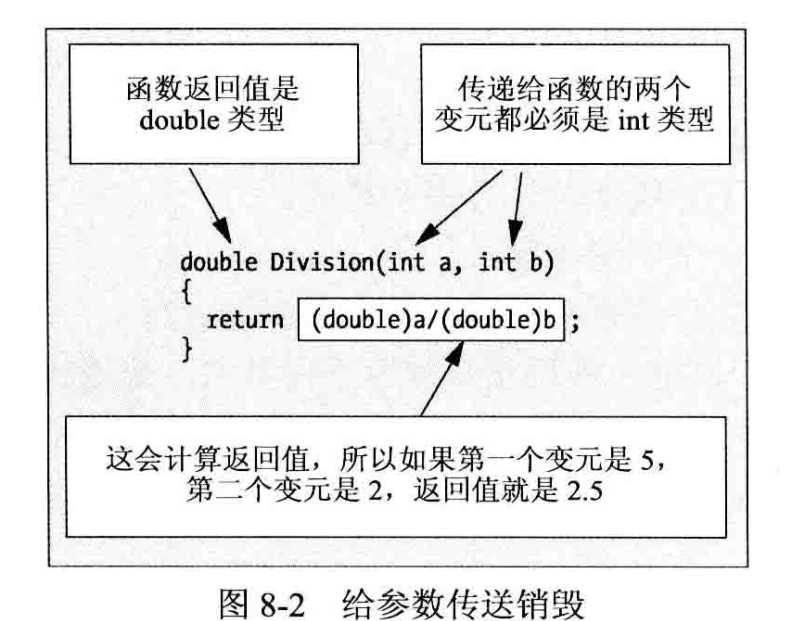
如果函数的变元类型不匹配对应参数的类型,编译器就会插入一个类型转换操作,将变元值的类型转换为参数的类型。这可能会截断变元值,例如把double类型的值传送给int类型的参数,所以这是一个危险的操作。如果编译器不能把变元转换为需要的类型,就会得到一条错误消息。
3. 指定返回值的类型
另一个常见的函数形式如下:
Return_type Function_name (List of Parameters - separated by commas)
{
// Statements..
}
Return_type指定了函数返回值的类型。如果在表达式中使用函数,或函数在赋值语句的右侧使用,则函数的返回值会取代该函数。函数的返回值可以指定为 C 语言中任何合法的类型,包括枚举类型和指针。
返回类型也可以是 void* ,表示指向 void 的指针。此时,返回值是一个地址值,但没有指定类型。希望返回一个能灵活返回指向各种类型的地址时,就可以使用这个类型,例如分配内存的 malloc() 函数。返回类型也可以指定为 void ,表示没有返回值。
注意:
第 11 章将介绍 structs 类型,它提供了把几个数据项作为一个单元来处理的方式。函数的参数可以是 struct 类型或指向 struct 的指针,也可以返回一个 struct 或指向 struct 的指针。
return 语句允许退出函数,从调用函数中发生调用的那一点继续执行。return 语句最简单的形式如下:
return;
这个形式的 return 语句用于返回类型声明为 void 的函数,它不返回任何值。较常见的 return 语句形式是:
return expression;
这个形式的 return 语句必须用于返回类型没有声明为 void 的函数,返回给调用程序的值是计算 expression 的结果,其类型应是给函数指定的返回类型。
警告:
如果函数的返回类型定义为 void ,却试图返回一个值,编译程序时就会得到一条错误消息。如果函数的返回类型没有定义为 void,而只使用了 return,编译器也会生成一条错误消息。
如果 expression 生成的值的类型不同于函数头声明的返回类型,编译器会将 expression 的类型转换成需要的类型。如果不能转换,编译器就生成一条错误消息。一个函数中可能有多条 return 语句,但每条 return 语句都必须提供一个可以转换为函数头中为返回值指定的类型的值。
注意:
调用函数不必识别或处理被调用函数返回的值。程序员负责确定如何使用函数调用的返回值。
给函数传送变元时,变元值不会直接传递给函数,而是先制作变元值的副本,存储在栈上,再使这个副本可用于函数,而不是使用初始值,如图8-4所示。
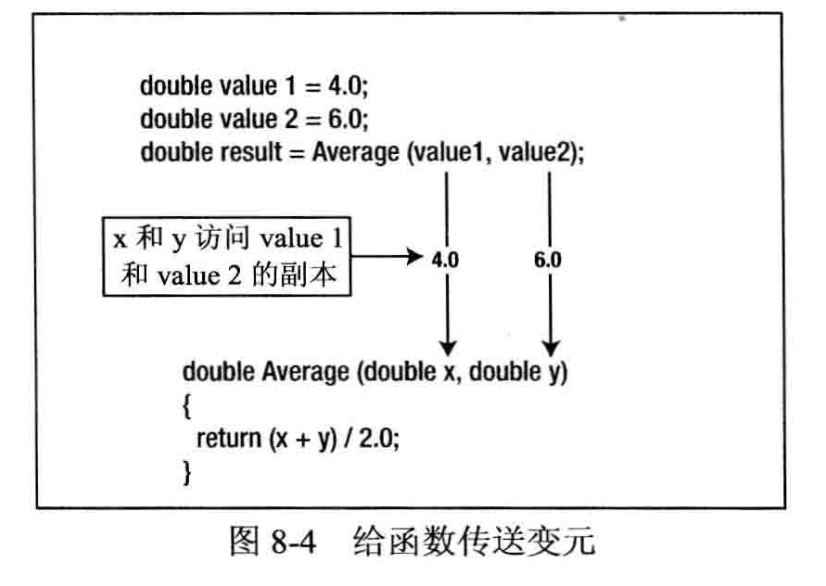
图 8-4 中的 Average() 函数仅计算其两个变元的平均值,这两个变元映射为参数 x 和 y。 Average() 函数不能访问调用该函数时传递为变元的变量 value1 和 value2,只能访问这两个变元值的副本。这表示函数不能修改存储在 value1 或 value2 中的值。这个机制是C语句中所有变元值传递给函数的方式,称为按值传递机制(pass-by-value mechanism)。
被调用函数修改属于调用函数的变量值的唯一方式是,把变量的地址接收为变元值。给函数传递地址时,它只是所传递地址的副本,而不是初始的地址。但是,副本仍是一个地址,仍引用最初的变量。这就是必须把变量的地址传递给 scanf_s() 的原因。不传递地址,该函数就不能在最初的变量中存储值。
把数组传递为变元时,按值传递机制的一个有趣结论是,第 5 章讨论数组时提到,数组名本身引用了数组的起始地址,但它不是指针,不能修改这个地址。但是,把数组名用作变元时,会制作该地址的副本,并将副本传递给函数。该副本现在只是一个地址,所以被调用函数可以用任意方式修改这个地址。当然,最初的数组地址不受影响。这不是推荐方式,但意味着可以用如下方式实现程序 8.3 中的 Sum() 函数:
double Sum (double x[], size_t n)
{
double sum = 0.0;
for (size_t i= 0 ; i <n; ++i)
sum += * (x++) ;
return sum;
}
这段代码把数组名 x 看作一个指针。这是合法的,因为给参数 x 传递为变元的任意值最终都是一个double* 类型的值。
从函数返回的值也是一个副本。这是必需的,因为在函数体内定义的自动变量和其他本地变量都会在函数返回时删除。程序8-3中的 GetData() 函数返回 nValues 的值, nValues 在函数结束时不再存在,但会制作其值的副本,传递回 main()。
在程序 8.3 的变体中,先定义 main()函数,再定义 average()、Sum()和 GetData()函数:
// #include & #define directives...
int main (void)
{
// Code in main () ...
}
double Average (double x[], size_t n)
{
return Sum (x, n) /n;
}
double Sum (double x[], size_t n)
{
// Statements...
}
size_t GetData(double *data, size_t max_count)
{
// Statements...
}
这段代码不会编译。编译器在遇到 Average() 函数的调用时,不知道该如何处理,因为那时 Average()函数还没有声明。在 main()中调用 GetData()时也是这样。编译器开始编译 Average()时, Sum()还没有定义,不能处理对这个函数的调用。为了编译这段代码,必须在main()的定义之前添加代码,告诉编译器 Average()、 Sum()和 GetData()函数的信息。
函数声明也称为函数原型,是一个定义函数基本特性的语句,它定义了函数的名称、返回值的类型和每个参数的类型。事实上,可以将它编写为与函数头一模一样,只是要在尾部加一个分号。函数声明也叫做函数原型,因为它提供了函数的所有外部规范。函数原型能使编译器在使用这个函数的地方创建适当的指令,检查是否正确地使用它。在程序中包含头文件时,这个头文件就会在程序中为库函数添加函数原型。例如,头文件<stdio.h>含有 printf()和 scanf()的函数原型。
为了使程序 8.3 的变体可以编译,只需要在函数 main()的定义前面添加其他 3 个函数的原型:
// #include & #define directives...
// Function prototypes
double Average (double x[], size_t n);
double Sum (double x[], size_t n);
size_t GetData(double *data, size_t max_count);
int main (void)
{
// Code in main () ...
}
double Average (double x[], size_t n)
{
return Sum (x, n) /n;
}
double Sum (double x[], size_t n)
{
// Statements...
}
size_t GetData(double *data, size_t max_count)
{
// Statements...
}
现在,编译器可以编译 main()中的 Average()函数调用,因为编译器知道该函数的所有特性,例如名称、参数类型和返回类型。在技术上,可以把 Average()函数的声明放在 main()函数体中,只是 Average()函数的声明必须放在该函数的调用之前,但事实上这种做法并不可行。函数原型一般放在源文件的开头处,而且在所有函数的定义和头文件之前。另外,在源文件中,函数原型在所有函数的外部,函数的作用域是从其声明处开始直到源文件的结尾。因此无论函数的定义放在什么地方,源文件中的任意函数都可以调用该文件中的其他函数 。
注意参数名不一定与函数定义中的参数名相同,甚至不需要在函数原型中包含参数名。在 GetData()原型中,为了显示出区别,故意忽略了参数名。这是可行的,但不推荐使用。注意参数类型 double*等价于函数定义中的参数类型 double[]。在函数原型中使用不同的参数名,一个用途是使原型中的参数名比较长,更容易理解;而在函数定义中,要使参数名短一些,代码比较简洁。
有时函数fun1()调用另一个函数fun2(), fun2()又调用了fun1()。此时必须给函数定义原型,程序才能编译。无论在什么地方调用,最好总是把函数的声明放在程序的源文件中。这有助于程序与设计保持一致,还可以防止在程序的另一部分调用函数时出错。当然, main()函数不需要函数原型,因为在程序开始执行时,这个函数会由主机环境调用。
前面介绍了如何把函数参数指定为指针类型,把地址作为相应的变元传递给函数。另外,如果函数修改在调用函数中定义的变量值,也需要使用指针变元。事实上这是唯一的方法。
前面还提到,把数组作为变元,通过指针参数传递给函数时,只传递了该数组的地址副本,而没有传递数组。函数中为数组元素定义的值可以在把该函数作为变元的函数中修改。被调用函数需要知道传递给它的数组的元素个数。这有两种方式:第一种方式是定义一个额外的参数,即数组的元素个数。对于带有指针参数 p 和元素个数 n 的函数,数组元素可以通过其地址来访问,它们的地址是 p 到 p+n-1。这种方式等价于传递了两个指针,一个是 p,指向数组的第一个元素;另一个是 p+n,指向最后一个元素后面的地址。这个机制在其他编程语言(如C++)中用得很多。第二种方式是在函数可以访问的最后一个数组元素中存储一个特别的唯一值。这个机制用于字符串,表示字符串的 char 数组在最后一个元素中存储了"0’。这个机制有时也可以应用于其他类型数据的数组。例如, 温度值数组可以在最后一个元素中存储-1000,标记数组的结束,因为这从来都不是一个有效的温度。
可以使用 const 关键字修饰函数参数,这表示函数将传送给参数的变元看做一个常量。由于变元是按值传送的,所以只有参数是一个指针时,这个关键字才有效。一般将 const 关键字应用于指针参数,指定函数不修改该变元指向的值。下面是带一个 const 参数的函数示例:
bool SendMessage (const char* pmessage)
{
// Code to send the message return true;
}
参数 pmessage 的类型是指向 const char 的指针。换言之,不能修改的是 char 值,而不是其地址。把 const 关键字放在开头,指定被指向的数据是常量。编译器将确认函数体中的代码没有使用pmessage 指针修改消息文本。也可以把指针本身指定为 const ,但这没有意义,因为地址是按值传送的,所以不能改变调用函数中的原始指针。
将指针参数指定为 const 有另一个用途。const 修饰符暗示,函数不修改指针指向的数据,因此编译器知道,指向常量数据的指针变元应是安全的。另一方面,如果不给参数使用 const 修饰符,对编译器而言,函数就可以修改变元指向的数据。将指向常量数据的指针作为变元传送给未声明为 const 的参数时,C编译器至少应给出一条警告消息。
提示:
如果函数不修改指针参数指向的数据,就把该函数参数声明为 const。这样,编译器就会确认,函数的确没有改变该数据。将指向常量的指针传送给函数时,还可以避免出现警告或错误消息。
当参数是指向指针的指针时,使用它就有点复杂了。此时,传递给该参数的变元是按值传递的,就像其他变元一样,所以无法把指针指定为const。但是,可以把指针指向的指针定义为const,防止修改指针指向的内容。但我们仅希望最终被指向的数据是const。对于指针的指针参数,下面是const一种可能的用途:
void sort (const char** str, size_t n);
这是 sort()函数的原型,其第一个参数是指向 const char 的指针的指针类型。把第一个参数看作一个字符串数组,则字符串本身是常量,它们的地址和数组的地址都不是常量。这是合适的,因为该函数会重新安排在数组中存储的地址,而不修改它们指向的字符串。
第二种可能的用途是:
void sort ( char *const *str, size_t n);
这里,第一个参数是指向 char 的常量指针的指针。变元是一个字符串数组,函数可以修改字符串,但不能修改数组中的地址。例如,函数可以用空格替换标点符号,但不能重新安排字符串在数组中的顺序。
对指针的指针参数使用常量的最后一种可能用途是:
size_t max_length (const char* const* str, size_t n);
在这个函数原型中,第一个参数是指向 const char 的常量指针的指针类型。数组中的指针是常量,它们指向的字符串也是常量。该函数可以访问数组,但不能以任何方式修改数组。这个函数一般返回字符串的最大长度,获得这个数据时不会修改任何内容。
试试看:使用指针传输数据
下面用更实际的方式练习使用指针给函数传递数据的方式,并复习第 7 章的程序 7.14 中排序字符串函数的修改版本。源代码除了定义 main()函数之外,还定义了 5 个函数。这里先列出了 main()函数的实现代码和函数原型,后面将讨论其他 5 个函数的实现方式。
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
#define BUF_LEN 256 // Input buffer size
#define INIT_NSTR 2 // Initial number of strings
#define NSTR_INCR 2 // increment to number to strings
char *str_in(); // Reads a string
void str_sort(const char **, size_t); // Sorts an array of strings
void swap(const char **, const char **); // Swaps two pointers
void str_out(const char *const *, size_t); // Outputs the strings、
void free_memory(char **, size_t); // Free all heap memory
int main(void) {
size_t pS_size = INIT_NSTR;
char **pS = calloc(pS_size, sizeof(char *));
if (!pS) {
printf("Failed to allocate memory for string pointers.In");
exit(1);
}
char **pTemp = NULL;
size_t str_count = 0;
char *pStr = NULL;
printf("Enter one string per line. Press Enter to end: \n");
while ((pStr = str_in()) != NULL) {
if (str_count == pS_size) {
pS_size += NSTR_INCR;
if (!(pTemp = realloc(pS, pS_size * sizeof(char *)))) {
printf("Memory allocation for array of strings failed. In");
return 2;
}
pS = pTemp;
}
pS[str_count++] = pStr;
}
str_sort(pS, str_count);
str_out(pS, str_count);
free_memory(pS, str_count);
return 0;
}
这里为代码使用的符号选择值,可以确保内存的重新分配发生得比较频繁。如果希望跟踪这个活动,可以添加 printf() 调用。在实际的程序中,所选的值应最小化重复的堆内存分配的可能性,以避免其系统开销。
把函数原型放在源文件的开头,函数的定义就可以采用任意顺序。字符串存储在堆内存中,指向每个字符串的指针存储在 ps 数组的一个元素中,该数组也在堆内存中。数组 pS 的初始容量可以容纳符号 INIT_NSTR 定义的指针个数。main() 的操作非常简单,它使用 str_in() 从键盘上读取字符串,调用 str_sort() 给字符串排序,调用 str_out() 把字符串按排序后的顺序输出,再调用 free_memory() 函数释放已分配的堆内存。
字符串通过str_in()从键盘上读取,该函数的实现代码如下:
char *str_in(void) {
char buf[BUF_LEN];
if (!gets_s(buf, BUF_LEN)) {
printf("\nError reading string. \n");
return NULL;
}
if (buf[0] == '\0') {
return NULL;
}
size_t str_len = strnlen_s(buf, BUF_LEN) + 1;
char *pString = malloc(str_len);
if (!pString) {
printf("Memory allocation failure.\n");
return NULL;
}
strcpy_s(pString, str_len, buf);
return pString;
}
返回类型是 char*,即指向字符串的指针。字符串读入本地数组 buf 中。给读取的字符串分配足够的堆内存,其地址存储在本地变量 pString 中。 buf 中的字符串复制到堆内存中,返回 pString 中存储的地址。如果读取了空字符串,函数就返回 NULL。在 main()中,字符串在一个循环中读取,当 str_in()返回 NULL 时,这个循环就结束。非 NULL 字符串地址存储在 ps数组的下一个可用元素中。如果数组已满,就调用 realloc() 函数,给数组增加 NSTR_INCR 个元素。已有的数据放在由 realloc() 分配的新内存中,即使它们可能不位于相同的地址中也是如此。
读取了所有的字符串后,就调用 str_sort() 函数把它们按升序存储。str_sort() 函数的实现代码如下:
void str_sort(const char **p, size_t n) {
bool sorted = false;
while (!sorted) {
sorted = true;
for (int i = 0; i < n - 1; ++i) {
if (strcmp(p[i], p[i + 1]) > 0) {
sorted = false;
swap(&p[i], &p[i + 1]);
}
}
}
}
这段代码使用冒泡排序法给字符串排序,与第 7 章的示例相同。对指向字符串的指针数组 ps 执行该过程,如图8-5所示。
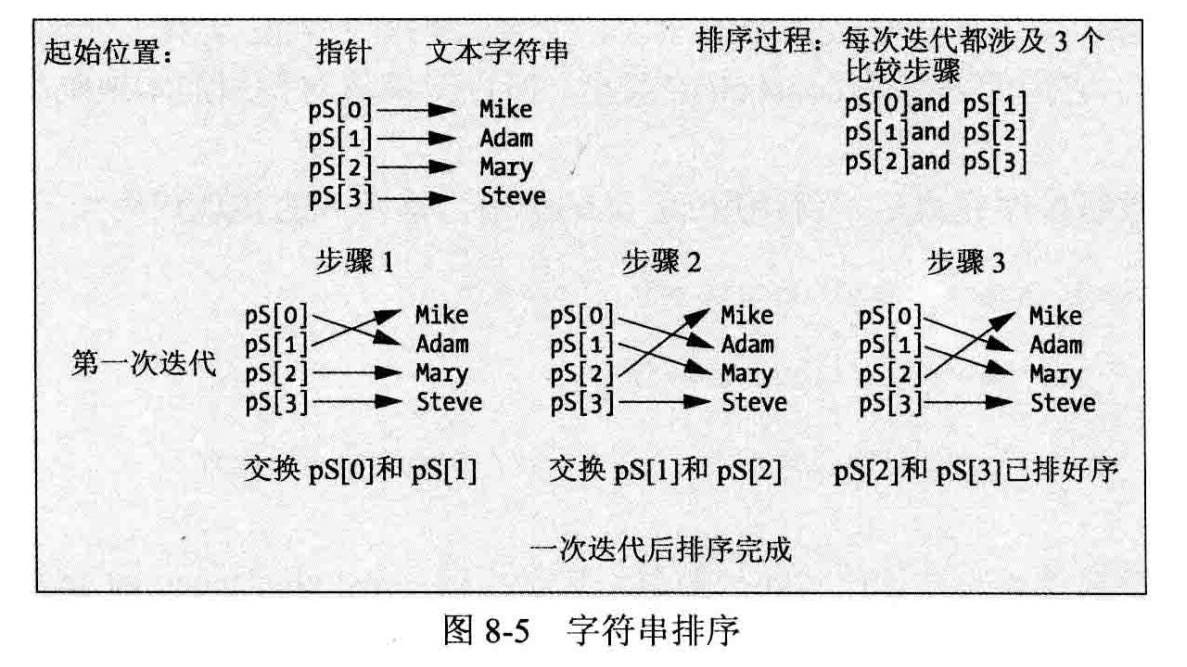
这个过程比较相邻的两个数组元素,如果它们的顺序不正确,就交换其位置。在图8-5所示的例子中,对所有元素进行第一次选代后,元素就排好序,但这个过程一般要重复多次。
str_sort() 的第一个参数是 const char** 类型,即指向 const char的指针的指针。这是一个指向字符串的指针数组,其中字符串是常量,但其地址不是常量。排序过程会重新安排存储在数组元素中的地址,使字符串以顺序排列。字符串本身不改变,也不修改它们在堆内存中的地址。第二个变元是数组元素指向的字符串个数,它是必需的,因为没有它,函数就无法确定有多少个字符串。注意在 str_sort() 函数中没有 return 语句。在执行到函数体的末尾时,就等价于执行一个没有返回表达式的 return 语句。显然,这仅适用于返回类型为 void 的函数。
str_sort() 函数调用 swap()交换两个指针。一定要清楚这个函数的作用,才能明白为什么使用这样的参数类型。注意,变元是按值传递的,所以必须把变量的地址传递给函数,函数才能修改调用函数中的值。swap() 函数的变元是 &p[i]和 &p[i+1],它们是 p[i]和 p[i+1]的地址,即指向这些元素的指针。这些元素是什么类型?它们是指向 const char的指针,其类型是 const char*。把这些放在一起,就有了swap()函数的参数类型 const char**,即指向 const char的指针的指针。必须以这种方式指定函数,因为swap(函数要修改p数组中的元素内容。如果在参数类型定义中只使用了一个*,且使用p[i]和p[i+1]作为变元,函数就会接收包含在这些元素中的内容,这可不是我们希望的。当然, const char**类型与 const char*[]类型相同,后者是 const char类型的数组。这里可以使用这两种类型中的任意一种,但必须编写 const char p1[],而不是 const char*[]pl。
swap()函数的实现代码如下:
void swap(const char **pl, const char **p2) {
const char *pT = *pl;
*pl = *p2;
*p2 = pT;
}
如果理解了使用这些参数类型的原因,交换代码就很容易理解了。函数交换了 pl 和 p2 的内容。它们的内容是 const char* 类型,所以交换值时使用的本地临时变量也使用这个类型。
字符串数组排序完成后,就调用str_out()输出,该函数的实现代码如下:
void str_out(const char *const *pStr, size_t n) {
printf("The sorted strings are:\n");
for (size_t i = 0; i < n; ++i)
printf("%s\n", pStr[i]);// Display a string
}
第一个参数是 const char* const* 类型,它是指向 const char 的 const 指针的指针。该函数只是访问数组变元,不修改数组中的指针或指针指向的内容,所以可以把数组元素和它们指向的内容指定为 const。第二个变元是要显示的字符串个数。函数体中的代码在前面解释过了,这里不再赘述。
main()中的最后一步是调用 free_memory(),释放已分配的所有堆内存。 free_memory() 的实现代码如下:
void free_memory(char **pS, size_t n) {
for (size_t i = 0; i < n; ++i) {
free(pS[i]);
pS[i] = NULL;
}
free(pS);
pS = NULL;
}
堆内存的释放分两个阶段。存储字符串的内存在 for 循环中选代数组元素,一个个地释放。每个指针指向的内容释放后,指针就重置为 NULL。字符串的所有内存都释放后,就调用一次free(),释放为存储字符串地址而分配的内存。
在本例的下载文件中添加了许多注释。对于包含几个函数的较长程序,这是一个很好的实践方式,确保阅读程序的人了解每个函数的作用。
这个程序的输出如下:
Enter one string per line. Press Enter to end:
Many a mickle makes a muckle.
Least said, soonest mended.
Pride comes before a fall.
A stitch in time saves nine.
A wise man hides the hole in his carpet.
The sorted strings are:
A stitch in time saves nine.
A wise man hides the hole in his carpet.
Least said, soonest mended.
Many a mickle makes a muckle.
Pride comes before a fall.
前面介绍了如何从函数中返回数值,其实返回的是该值的副本。从函数中返回指针是一个非常强大的功能,因为它允许返回一整组值,而不仅仅返回一个值。在前面的示例中, str_in()函数返回一个指向字符串的指针,当然,此时也是返回指针值的副本。由此可能得到一个错误的结论:函数的返回值不会出错。尤其是,返回指针有一些特定的风险。下面先看一个非常简单的例子,说明其中一个风险。
试试看:从函数中返回数值
这里使用加薪作为这个例子的基础,因为它是一个大众化的主题。
#include <stdio.h>
long *IncomePlus(long *pPay);
int main(void) {
long your_pay = 30000L;
long *pold_pay = &your_pay;
long *pnew_pay = NULL;
pnew_pay = IncomePlus(pold_pay);
printf("Old pay=$%ld\n", *pold_pay);
printf(" New pay =$%ld\n", *pnew_pay);
return 0;
}
long *IncomePlus(long *pPay) {
*pPay += 10000L;
return pPay;
}
执行这个程序,输出如下:
old pay =$40000
New pay = $40000
在 main()函数中,为变量 your_pay 设置一个初始值,定义两个用于 IncomePlus()函数的指针, IncomePlus()函数用来增加 your_pay。一个指针初始化为 your_pay的地址,另一个初始化为 NULL,因为它接收 IncomePlus()函数返回的地址。
输出看起来不错,但不正确。如果不知道原来的薪水是 $30 000,这个输出看起来好像薪水一点都没有增加。因为函数 IncomePlus()通过指针 pold_pay修改了 your_pay的值,原来的值已经改变了。很明显,两个指针 pold_pay和 pnew_pay 引用相同的位置:your_pay.这是函数 IncomePlus()中的下述语句的结果:
return pPay;
这会返回函数调用时接收到的指针值,即 pold_pay 内的地址。结果是原来的薪水增长了-这就是指针的作用。
但是,这不是返回指针的唯一问题。下面是一个变体。
为了避免干扰变元指向的变量,可以考虑在函数 IncomePlus() 中使用本地存储器存储返回值。对这个例子 IncomePlus() 函数做如下小修改:
long *IncomePlus(long *pPay) {
long pay = 0;
pay = *pPay + 10000L;
return &pay;
}
编译这个例子,可能会得到一条警告消息。但运行程序,得到的结果如下(由于计算机不同,得到的结果可能不同,但该结果可能是正确的):
Old pay=$30000
进程已结束,退出代码-1073741819 (0xC0000005)
pay 的值$27 467 656 让人吃惊。但在抱怨此类错误前可能会犹豫。如前所述,在不同的计算机上可能会得到不一样的结果,这次可能是正确的结果。编译这个版本的程序,应该会得到一个警告,例如“指向本地 pay的指针是无效的返回值”。这是因为这个程序返回了变量 pay的地址,在退出函数 IncomePlus() 时,它超出了作用域,使 pay的新值非常大-这个值是一个垃圾值,是其他程序遗留下来的。这是很容易犯的错误,如果编译器没有提出警告,就很难找出这个错误。
这看起来是正确的,但事实上程序中有一个严重的错误。虽然变量 pay 超出了作用域,因此不再存在,但它所占的内存尚未被重新使用。在这个例子中,显然某些对象使用了 pay 变量使用过的这个内存,生成了巨大的输出值。使用如下定律可以避免这类问题。
定律:
绝不返回函数中本地变量的地址。
如何实现 IncomePlus() 函数?如果要求函数修改传递给它的地址,第一个实现方式就很好。但如果不想改变地址,就应只返回 pay 的新值,而不是指针。调用程序必须存储这个返回值,而不是地址。
如果要将 pay 的新值存储到另一个位置中,函数 IncomePlus()就可以用 malloc()函数为它分配空间,并返回这个内存的地址。然而,应该注意调用函数必须释放该内存。最好给函数传送两个变元,一个变元是初始 pay的地址,另一个是存储新 pay的地址。这样,调用函数就可以支配内存了。如果因为某种原因必须传递指向 pay初始值的指针,就应把参数的类型指定为 const long*来保护它。
将执行期间分配内存与释放内存分开,有时会造成内存泄漏。在循环中重复调用的函数动态分配内存后,却没有释放它,就会出现内存泄漏。结果,越来越多可用的内存被占据了,当没有内存可用时,程序就会崩溃。应尽可能使分配内存的函数在使用完内存后就释放它。如果不能由函数释放内存,就要编写代码,释放动态分配的内存。
本章尚未完成函数的讨论,所以第9章的最后将通过另一个例子介绍使用函数的更多内容。下面总结创建和使用函数时的重点:
- C程序由一个或多个函数组成,其中一个是main()函数。该函数永远是执行的起点,操作系统通过一个用户命令调用它。
- 函数是程序中独立的一块自包含代码。函数的名称采用标识符名称的形式,由一系列字母和数字组成,第一个字符必须是字母(下划线算是字母)。
- 函数定义由函数头和函数体组成。函数头定义了函数的名称、函数返回值的类型及函数中所有参数的类型和名称。函数体含有函数的可执行语句,定义了这个函数的功能。
- 在函数中声明的所有变量都是函数的本地变量。
- 函数原型是一个以分号终止的声明语句,用以定义函数的名称、返回类型和函数的参数类型。在可执行代码中,如果函数调用出现在函数定义之前,就需要函数原型给编译器提供函数相关信息。
- 在源文件中使用函数之前,应该先定义这个函数,或用函数原型声明这个函数。
- 将指针参数指定为const就会告诉编译器,这个函数不改变该参数指向的数据。
- 函数变元的类型必须符合函数头中对应的参数。如果指定参数的类型是int,但传送了double类型的值,该值就会被截断,删除小数部分。
- 有返回值的函数可以用在表达式中,就如同它是一个与返回值类型相同的值一样,
- 在调用函数中,是将变元值的副本传给函数,而不是传送原始值。这种给函数传送数据的方式称为按值传递机制。
- 如果函数要修改在调用函数中定义的变量,就需要将这个变量的地址作为变元传送。
这些涵盖了创建定制函数的重点。第9章将介绍使用函数的其他技巧,在真实的例子中使用函数。