Beginning C , Fifth Edition 第7章:指针
第 6 章已提到过指针,还给出使用指针的提示。本章深入探索这个主题,了解指针的功用。本章将介绍许多新概念,所以可能需要多次重复某些内容。本章很长,需要花一些时间学习其内容,用一些例子体验指针。指针的基本概念很简单,但是可以应用它们解决复杂的问题。指针是用C语言高效编程的一个基本元素。
本章的主要内容:
- 指针的概念及用法
- 指针和数组的关系
- 如何将指针用于字符串
- 如何声明和使用指针数组
- 如何编写功能更强的计算器程序
指针是 C 语言中最强大的工具之一,它也是最容易令人困惑的主题,所以一定要在开始时正确理解其概念,在深入探讨指针时,要对其操作有清楚的认识。
第 2 和第 5 章讨论内存时,谈到计算机如何为声明的变量分配一块内存。在程序中使用变量名引用这块内存,但是一旦编译执行程序,计算机就使用内存位置的地址来引用它。这是计算机用来引用“盒子(其中存储了变量值)“的值。
请看下面的语句:
int number = 5;
这条语句会分配一块内存来存储一个整数,使用 number 名称可以访问这个整数。值 5 存储在这个区域中。计算机用一个地址引用这个区域。存储这个数据的地址取决于所使用的计算机、操作系统和编译器。在源程序中,这个变量名是固定不变的,但地址在不同的系统上是不同的。
可以存储地址的变量称为指针(pointers),存储在指针中的地址通常是另一个变量,如图7-1所示。指针 pnumber 含有另一个变量 number 的地址,变量 number 是一个值为 99 的整数变量。存储在 pnumber 中的地址是 number 第一个字节的地址。“指针”这个词也用于表示一个地址,例如"strcat_s()函数返回一个指针”。
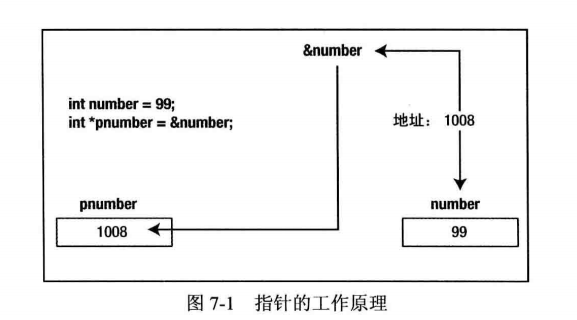
首先,知道变量 pnumber 是一个指针是不够的,更重要的是,编译器必须知道它所指的变量类型。没有这个信息,根本不可能知道它占用多少内存,或者如何处理它所指的内存的内容。char 类型值的指针指向占有一个字节的值,而 long 类型值的指针通常指向占有4个字节的值。因此,每个指针都和某个变量类型相关联,也只能用于指向该类型的变量。所以如果指针的类型是 int,就只能指向 int 类型的变量,如果指针的类型是 float,就只能指向 float 类型的变量。一般给定类型的指针写成 type*,其中 type 是任意给定的类型。
每个指针都和某个变量类型相关联
类型名 void 表示没有指定类型,所以 void* 类型的指针可以包含任意类型的数据项地址。类型 void* 常常用做参数类型,或以独立于类型的方式处理数据的函数的返回值类型。任意类型的指针都可以传送为 void* 类型的值,在使用它时,再将其转换为合适的类型。例如, int 类型变量的地址可以存储在 void* 类型的指针变量中。要访问存储在 void* 指针所指地址中的整数值,必须先把指针转换为 int* 类型。本章后面介绍的 malloc() 库函数分配在程序中使用的内存,返回 void* 类型的指针。
以下语句可以声明一个指向 int 类型变量的指针:
int *pnumber;
pnumber 变量的类型是 int *,它可以存储任意 int 类型变量的地址。该语句还可以写作:
int* pnumber;
这条语句的作用与上一条语句完全相同,可以使用任意一个,但最好始终使用其中的一个。
这条语句创建了 pnumber 变量,但没有初始化它。未初始化的指针是非常危险的,比未初始化的普通变量危险得多,所以应总是在声明指针时对它进行初始化。重写刚才的声明,初始化 pnumber ,使它不指向任何对象:
int *pnumber = NULL;
NULL 是在标准库中定义的一个常量,对于指针它表示 0,NULL 是一个不指向任何内存位置的值。这表示,使用不指向任何对象的指针,不会意外覆盖内存。NULL 在头文件<stddef.h>. <stdib.h>、 <stdio.h>、<string.h>、<time.h>、<wchar.h>和<locale.h>中定义,只要编译器不能识别NULL,就应在源文件中包含<stddef.h>头文件。
如果用已声明的变量地址初始化 pointer 变量,可以使用寻址运算符&,例如:
int number = 99;
int *pnumber = &number;
pnumber 的初值是 number 变量的地址。注意, number 的声明必须在 pnumber 的声明之前。否则,代码就不能编译。编译器需要先分配好空间,才能使用 number 的地址初始化 pnumber 变量。
指针的声明没有什么特别之处。可以用相同的语句声明一般的变量和指针,例如:
double value,*pVal,fnum;
这条语句声明了两个双精度浮点数变量 value 和 fnum,以及一个指向 double 的变量 pVal,从该语句中可以看出,只有第2个变量 pVal 是指针,考虑如下语句:
int *p,q;
上述语句声明了一个指针p和一个变量q,两者都是int类型。把p和q都当做指针是一个很常见的错误。
使用间接运算符*可以访问指针所指的变量值。这个运算符也称为取消引用运算符(dereferencing operator),因为它用于取消对指针的引用。假设声明以下的变量:
int number = 15;
int *pointer = &number;
int result =0;
pointer 变量含有 number 变量的地址,所以可以在表达式中使用它计算 result 的新值,如下:
int result =*pointer + 5;
表达式 *pointer 等于存储在 pointer 中的地址的值。这是存储在 number 中的值 15,所以 result 是15+5,等于20.
理论先讲到这里。下面的小程序将凸显指针变量的某些特性。
间接运算符*也是乘的符号,还可以用于指定指针类型。编译器不会混淆它们。编译器会根据星号出现的位置确定它是间接运算符还是乘号,还是类型指定语句的一部分。上下文决定了它的含义.
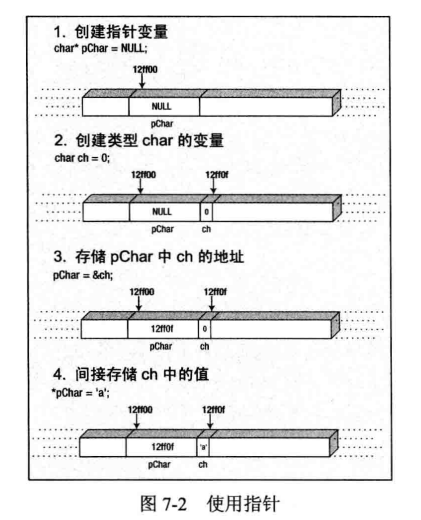
图7-2说明了指针的用法。这里指针的类型是char*,即指向char的指针。pChar变量只能存储char本例的地址。存储在c中的值通过指针来修改。
#include <stdio.h>
int main(void) {
int number = 0;
// pnumber 变量是个指针变量
int *pnumber = NULL;
number = 10;
printf("number's address: %p\n", &number);
printf("number's value: %d\n\n", number);
pnumber = &number;
// pnumber 变量的地址
printf("pnumber's address: %p\n", (void *) &pnumber);
// pnumber 变量的大小
printf("pnumber's size: %zd bytes\n", sizeof(pnumber));
// pnumber 变量存储的值(另一个变量 number 的地址)
printf("pnumber's value: %p\n", pnumber);
// 通过 取消引用运算符 获得 pnumber 变量存储的地址的变量的值
printf("value pointed to: %d\n", *pnumber);
return 0;
}
可以通过指针 pnumber 访问 number 的内容,所以可以在算术语句中使用取消引用的指针,例如:
*pointer += 25;
上述语句将变量 pnumber 所指向的地址中的值增加 25。星号 * 表示访问 pnumber 变量所指向的内容。这里它是变量 number 的内容。变量 pnumber 能存储任何 int 变量的地址。这表示可以用下面的语句改变 pnumber 指向的变量:
int value =999;
pnumber= &value;
重复之前的语句:
*pointer += 25;
该语句操作的是新的变量 value, value 的新值是1024,这表示指针可以包含同一类型的任意变量的地址,所以使用一个指针变量可以改变其他许多变量的值,只要它们的类型与指针相同。
可以改变指针中存储的地址,但不允许使用指针改变它指向的值。
int main(void) {
long value = 9999L;
const long *pvalue = &value;
// *pvalue = 8888L; // 只读变量不可赋值
value = 7777L; // pvalue 指向的值不能改变,但可以对 value 进行任意操作。
long number = 8888L;
pvalue = &number; // 指针本身不是常量
/*
* 指向常量的指针
* 可以改变指针中存储的地址,但不允许使用指针改变它指向的值
* */
return 0;
}
声明指针时,可以使用const关键字指定,该指针指向的值不能改变。下面是声明const指针的例子:
long value = 9999L;
const long *pvalue = &value; // Defines a pointer to a constant
把 pvalue 指向的值声明为 const,所以编译器会检查是否有语句试图修改 pvalue 指向的值,并将这些语句标记为错误。例如,下面的语句就会让编译器生成一条错误信息:
*pvalue = 8888L;// Error - attempt to change const location
pvalue 指向的值不能改变,但可以对 value 进行任意操作。
long value =7777L;
改变了 pvalue 指向的值,但不能使用 pvalue 指针做这个改变。当然,指针本身不是常量,所以仍可以改变它指向的值:
long number =8888L;
pvalue = &number;// OK-changing the address in pvalue
这会改变指向 number 的 pvalue 中的地址,仍然不能使用指针改变它指向的值。可以改变指针中存储的地址,但不允许使用指针改变它指向的值。
当然,也可以使指针中存储的地址不能改变。此时,在指针声明中使用const关键字的方式略有区别。下面的语句可以使指针总是指向相同的对象:
int count = 43;
int *const pcount =&count;// Defines a constant pointer
第二条语句声明并初始化了 pcount ,指定该指针存储的地址不能改变。编译器会检查代码是否无意中把指针指向其他地方,所以下面的语句会在编译时生成一条错误信息:
int count = 43;
int *const pcount =&count;// Defines a constant pointer
int item = 34;
pcount =&item;
但使用 pcount,仍可以改变 pcount 指向的值:
*pcount =345;
这条语句通过指针引用了存储在 count 中的值,并将其改为 345。还可以直接使用 count 改变这个值。
可以创建一个常量指针,它指向一个常量值:
int item =25;
const int *const pitem = &item;
pitem 是一个指向常量的常量指针,所以所有的信息都是固定不变的。不能改变存储在 pitem 中的地址,也不能使用 pitem 改变它指向的内容。但仍可以直接修改 item 的值。如果希望所有的信息都固定不变,可以把 item 指定为 const.
const long *pvalue long const *pvalue
可以改变指针中存储的地址,但不允许使用指针改变它指向的值。
int *const pcount
指针中存储的地址不能改变
const int *const pitem
所以所有的信息都是固定不变的。不能改变存储在 pitem 中的地址,也不能使用 pitem 改变它指向的内容
const 离变量名近就是用来修饰指针变量的,离变量名远就是用来修饰指针指向的数据,如果近的和远的都有,那么就同时修饰指针变量以及它指向的数据。
我们已经开始编写相当大的程序了。程序越来越大,就越难记住哪个是一般变量,哪个是指针。因此,最好将p作为指针名的第一个字母。如果严格遵循这个命名方法,肯定很清楚哪个变量是指针。
下面复习一下什么是数组,什么是指针:
- 数组是相同类型的对象集合,可以用一个名称引用。例如,数组scores[50]可以含有 50 场篮球季赛的比分。使用不同的索引值可以引用数组中的每个元素。scores[0]是第一个分数, scores[49]是最后一个分数。如果每个月有 10 场比赛,就可以使用多维数组scores[12][10]。如果一月开始比赛,则五月的第3场比赛用scores[5][2]引用。
- 指针是一个变量,它的值是给定类型的另一个变量或常量的地址。使用指针可以在不同的时间访问不同的变量,只要它们的类型相同即可。
数组和指针似乎完全不同,但它们有非常密切的关系,有时还可以互换。下面考虑字符串。字符串是char类型的数组。如果用scanf_s()输入一个字符,可以使用如下语句:
char single =0;
scanf_s("%c", &single, sizeof (single) );
这里, scanf_s() 需要将寻址运算符&用于single,因为scanf_s()需要存储输入数据的地址;否则它就不能修改地址。然而,如果读入字符串,可以编写如下代码:
char multiple [10];
scanf_s("%s", multiple, sizeof (multiple));
这里不需要使用&运算符,而使用了数组名称,就像指针一样。如果以这种方式使用数组名称,而没有带索引值,它就引用数组的第一个元素的地址。但数组不是指针,它们有一个重要区别:可以改变指针包含的地址,但不能改变数组名称引用的地址。
下面通过几个例子来了解数组和指针如何一起使用。这些例子串在一起,构成一个完整的练习。通过这些练习,很容易掌握指针的基本概念及其和数组的关系。
,这个例子进一步说明了,数组名称本身引用了一个地址,执行以下程序:
// Program 7.4 Arrays and pointers
#include <stdio.h>
int main (void){
char multiple[] ="My string";
char *p = &multiple [0];
printf ("The address of the first array element : %p\n", p);
p = multiple;
printf ("The address obtained from the array name: p\n", multiple);
return o;
}
在某台计算机上的输出如下所示:
The address of the first array element : 000000000012ff06
The address obtained from the array name: 000000000012ff06
可以从这个程序的输出中得到一个结论: &multiple[0]会产生和multiple表达式相同的值。这正是我们期望的,因为multiple等于数组第一个字节的地址, &multiple[0]等于数组第一个元素的第一个字节,如果它们不同,才令人惊讶。如果p设置为multiple,而multiple的值与&multiple[0]相同,那么p+1等于什么。试试下面的例子。
// Program 7.5 Incrementing a pointer to an array
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <string.h>
int main (void){
char multiple[] ="a string";
char *p = multiple;
for(int i=0; i < strnlen s(multiple, sizeof (multiple)) ; ++i)
printf ("multiple[%d] =c *(p+%d) = %c &multiple [%d] = %p p+%d=%p\n",i, multiple[i], i, *(p+i), i, amultiple[i], i, p+i);
return 0;
}
输出如下所示:
multiple [0] = a *(p+0) =&multiple[0] = 000000000012feff p+0 = 000000000012feff
multiple [1] = *(p+1) =&multiple[1] = 000000000012ff00 p+1 = 000000000012ff00
multiple [2] = s *(p+2) =&multiple[2] = 000000000012ff01 p+2 = 000000000012ff01
multiple [3] = t *(p+3) =&multiple[3] = 000000000012ff02 p+3 = 000000000012ff02
multiple [4] = r *(p+4) =&multiple[4] = 000000000012ff03 p+4 = 000000000012ff03
multiple [5] = I *(p+5) =&multiple[5] = 000000000012ff04 p+5 = 000000000012ff04
multiple [6] = n *(p+6) =&multiple[6] = 000000000012ff05 p+6 = 000000000012ff05
multiple [7] = g *(p+7) =&multiple[7] = 000000000012ff06 p+7 = 000000000012ff06
注意输出中右边的地址列表。p 设置为 multiple 的地址, p+n 就等于 multiple + n ,所以 multiple[n] 与 *(multiple+n) 是相同的。地址加上了 1,对于元素占用一个字节的数组来说,这正是我们期望的。从输出的两列中可以看出, *(p+n)是给p中的地址加上整数 n,再对得到的地址取消引用,就计算出了 与multiple[n]相同的结果。
试试看不同类型的数组
// Program 7.5 Incrementing a pointer to an array
#include <stdio.h>
int main (void){
long multiple[] = {15L,25L,35L,45L};
long *p = multiple;
for (int i=0; i < sizeof (multiple) /sizeof (multiple[0]) ; ++i)
printf ("address p+%d (&multiple[%d]) : %llu * (p+%d) value: %d\n", i, i, (unsigned long long) (p+i), i, *(p+i));
printf ("\n Type long occupies: %d bytes\n", (int) sizeof (1ong));
return 0;
}
输出如下所示:
address p+0 (&multiple [0]): 1244928 * (p+0) value: 15
address p+1 (&multiple [1]): 1244932 * (p+1) value: 25
address p+2 (&multiple [2]): 1244936 * (p+2) value: 35
address p+3 (&multiple [3]): 1244940 * (p+3) value: 45
Type long occupies: 4 bytes
这次,指针 p 设置为 multiple 的地址,而 multiple 是 long 类型的数组。该指针最初包含数组中第一个字节的地址,也就是元素 multiple[0] 的第一个字节。这次地址转换为 unsigned long long 后,用%llu转换说明符显示,所以它们都是十进制值,这将易于看出后续地址的区别。
注意看输出。在这个例子中, p 是 1244928, p+1 是 1244932 ,而 1244932 比 1244928 大 4,但我们仅给p加上了 1,这并没有错。编译器知道,给地址值加 1 时,就表示要访问该类型的下一个变量。这就是为什么声明一个指针时,必须指定该指针指向的变量类型。char 类型存储在一个字节中, long 变量一般占用4个字节。在计算机上声明为 long 的变量占4个字节,给 long 类型的指针加 1,结果是给地址加 4,因为 long 类型值占 4 个字节。如果计算机在 8 个字节中存储 long 类型,则给指向 long 的指针加 1,会给地址值加 8.
这个循环可以执行,因为表达式 multiple 和 multiple+i 都等于一个地址。我们输出这些地址的值,再使用*运算符输出这些地址存储的值。地址的算术运算规则与指针p相同。给 multiple 加1,会得到数组中下一个元素的地址,即内存中 multiple 后面的 4 个字节。但注意,数组名称是一个固定的地址,而不是一个指针。可以在表达式中使用数组名及其引用的地址,但不能修改它。
前面讨论的都是一维数组与数组的关系,二维或多维数组是否相同?它们在某种程度上是相同的。然而,指针和数组名称之间的差异变得更为明显。考虑第5章末尾在井字程序中使用的数组。数组声明如下:
char board [3] [3] ={
{'1','2','3"},
{'4','5','6'},
{'7','8','9'}
};
二维数组和指针
// Program 7.7 Two-dimensional arrays and pointers
#include <stdio.h>
int main (void){
char board [3] [3] ={
{'1','2','3"},
{'4','5','6'},
{'7','8','9'}
};
printf ("address of board: %p\n", board);
printf ("address of board [0] [0] : %p\n", &board [0] [0]);
printf ("value of board[0]: %p\n", board [0]);
return 0;
}
输出如下所示:
address of board: 000000000012ff07
address of board[0] [0] : 000000000012ff07
value of board[0]: 000000000012ff07
看图:
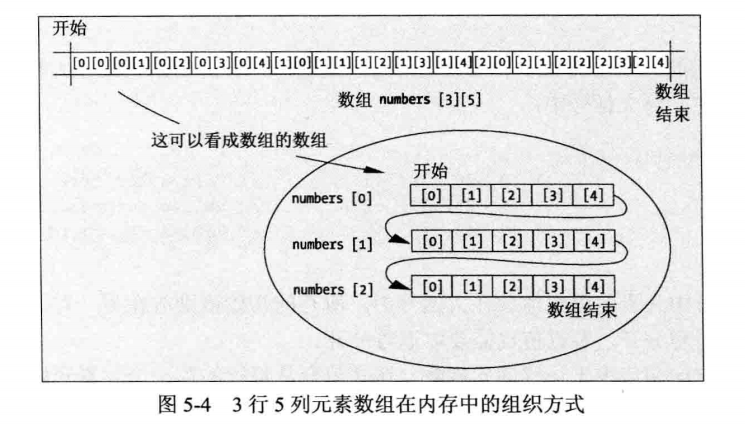
可以看到, 3个输出值都是相同的,从中可以得到什么推论?声明一维数组x[n1]时,[n1]放在数组名称之后,告诉编译器它是一个有n1个元素的数组。声明二维数组y[n1][n2]时,编译器就会创建一个大小为 n1 的数组,它的每个元素是一个大小为n2的数组.
如第5章所述,声明二维数组时,就是在创建一个数组的数组。因此,用数组名称和一个索引值访问这个二维数组时,例如board[0],就是在引用一个子数组的地址。仅使用二维数组名称,就是引用该二维数组的开始地址,它也是第一个子数组的开始地址。
总之, board, board[0]和&board[0][0]的数值相同,但它们并不是相同的东西: board是char型二维数组的地址, board[0]是char型一维子数组的地址,它是 board 的一个子数组, &board[0][0] 是char 型数组元素的地址。最近的加油站有61/2英里远,与帽子尺寸61/2英寸并不是一回事。也就是说,表达式 board[1] 和 board[1][0] 的地址相同。这很容易理解,因为 board[1][0] 是第二个子数组 board[1] 的第一个元素。
但是,用指针记号获取二维数组中的值时,仍然必须使用间接运算符,但要非常小心。如果改变上面的例子,显示第一个元素的值,就知道原因了:
// Program 7.7A Two-dimensional arrays and pointers
#include <stdio.h>
int main (void){
char board [3] [3] ={
{'1','2','3"},
{'4','5','6'},
{'7','8','9'}
};
printf ("value of board [0] [0] : %c\n", board[0][0]);
printf ("value of *board[0] : %c\n", board[0]);
printf ("value of **board : %c\n", **board) ;
return 0;
输出如下所示:
value of board[0] [0] : 1
value of *board[0] : 1
value of **board : 1
可以看到,如果使用board获取第一个元素的值,就需要使用两个间接运算符 *board .如果只使用一个,只会得到子数组的第一个元素,即 board[0] 引用的地址。多维数组和它的子数组之间的关系如图7-3所示。
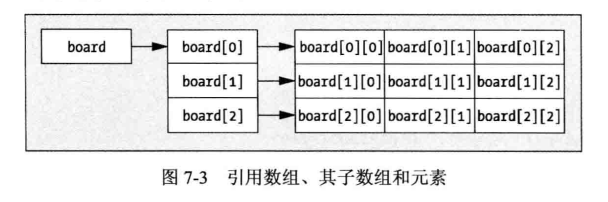
如图7-3所示,board 引用子数组中第一个元素的地址 , 而board[0]. board[1] 和 board[2] 引用对应子数组中第一个元素的地址。用两个索引值访问存储在数组元素中的值。明白了多维数组是怎么回事,下面看看如何使用 board 得到数组中的所有值。
注意:
尽管可以把二维数组看作一维数组的数组,但这不是在内存中布置二维数组的方式。,二维数组的元素存储为一个很大的一维数组,编译器确保可以像一维数组的数组那样访问它。
// Program 7.8 Getting values in a two-dimensional array
#include <stdio.h>
int main (void){
char board [3] [3] ={
{'1','2','3"},
{'4','5','6'},
{'7','8','9'}
};
// List all elements of the array
for(int i=o ; i< 9 ; ++i)
printf (" board: %c\n", *(*board + i));
return 0;
}
输出如下所示:
board: 1
board: 2
board: 3
board: 4
board: 5
board: 6
board: 7
board: 8
board: 9
这个程序要注意在循环中取消引用 board 的方法:
printf (" board: %c\n", *(*board + i));
可以看到,使用表达式 *(*board+i) 可以得到一个数组元素的值。括号中的表达式 *board+i 会得到board 数组中偏移量为 i 的元素的地址
只使用 board,就是在使用char** 类型的地址值。取消对 board 的引用,会得到相同的地址值,但其类型是 char*,给它加i会得到一个 char* 的地址,它是内存中的第 i 个元素,即数组中的一个字符。取消对它的引用,会得到该地址中存储的内容。
括号在这里是很重要的。省略它们会得到 board 所指向的值(即存储在 board 中的地址所引用的值)再加上 i 的值。因此,如果 i 的值是2, *board+i 会得到数组的第一个元素值加 2,我们真正想要的是将 i的值加到 board 中的地址,然后对这个新地址取消引用,得到一个值。
下面去掉例子中的括号,看看会发生什么。改变数组的初值,使字符变成从 9 到 1.如果去掉printf()函数调用中表达式的括号:
printf (" board: %c\n", **board + i);
输出如下所示:
board: 9
board: :
board: ;
board: <
board: =
board: >
board: ?
board: @
board: A
这是因为i的值加到数组 board 中的第一个元素(这个元素用表达式 **board 来访问)上。在ASCI表中,得到的字符是从9到A'.
另外,如果使用表达式**(board+i),一样会导致错误的结果。此时, **(board+0) 指向 board[0][0],而 **(board+1) 指向 board[1][0], **(board+2) 指向 board[2][0]。如果增加的数值过大,就会访问数组以外的内存位置,因为这个数组没有第4个元素。
前面通过指针的表示法用数组名称引用二维数组,现在学习使用声明为指针的变量。如前所述,这有非常大的区别。如果声明一个指针,给它指定数组的地址,就可以用该指针访问数组的成员。
// Program 7.9 Getting values in a two-dimensional array
#include <stdio.h>
int main (void){
char board [3] [3] ={
{'1','2','3"},
{'4','5','6'},
{'7','8','9'}
};
char *pboard = *board; // A pointer to char
for(int i=o ; i< 9 ; ++i)
printf (" board: %c\n", *(pboard + i));
return 0;
}
输出和程序7.8相同。
代码说明
这里用数组中第一个元素的地址初始化指针,然后用一般的指针算术运算遍历整个数组:
char *pboard = *board; // A pointer to char
for(int i=o; i<9; ++i)
printf (" board: c\n", *(pboard+i));
注意,取消了对board的引用(board),得到了需要的地址,因为board是 char* 类型,是指针的指针,是子数组 board[0] 的地址,而不是一个元素的地址(它必须是char*类型).可以用以下的方式初始化指针pboard:
char *pboard = *board[0][0];
效果相同。用下面的语句初始化指针pboard:
pboard = board;
这是错误的。如果这么做,至少会得到编译器的警告,理想情况下,它根本不会编,译。严格地讲,这是不合法的,因为 pboard 和 board 有不同的间接级别。这个专业术语的意思是 pboard 指针引用的地址包含一个 char 类型的值,而 board 引用一个地址,那个地址引用另一个含有 char 类型值的地址。 board 比pboard 多了一级。因此, pboard 指针需要一个*,以获得地址中的值,而 board 需要两个*。一些编译器允许这么用,但是会给出一条警告信息。然而,这是很糟的用法,不应这么用!
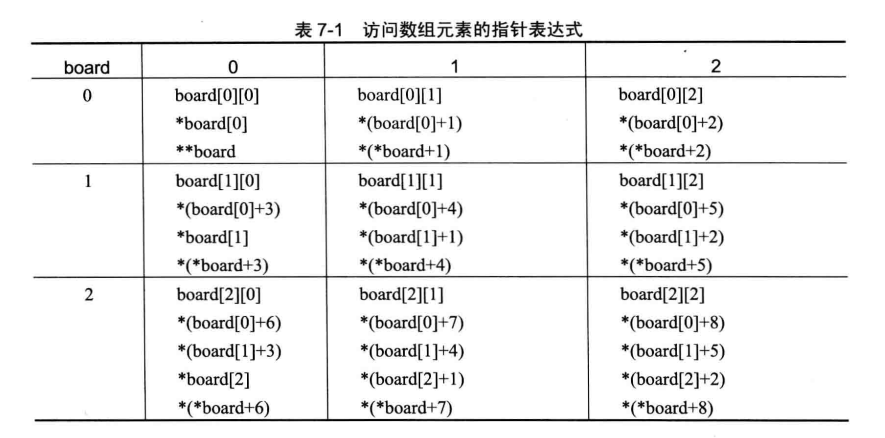
可以使用几种方法访问二维数组的元素。表7-1列出了访问 board 数组的方法。最左列包含 board 数组的行索引值,最上面的一行包含列索引值。表中对应于给定行索引和列索引的项列出了引用该元素的各种表达式。
指针是一个非常灵活且强大的编程工具,有非常广泛的应用。大多数C程序都在某种程度上使用了指针。c语言还有一个功能:动态内存分配,它依赖指针的概念,为在代码中使用指针提供了很强的激励机制,它允许在执行程序时动态分配内存。只有使用指针,才能动态分配内存
。大多数产品程序都使用了动态内存分配。例如电子邮件客户端在检索电子邮件时,事先并不知道有多少封电子邮件,也不知道每封邮件需要多少内存。电子邮件客户端在运行期间会得到足够的内存,来管理电子邮件的数量和大小。
第5章的一个程序计算一组学生的平均分,当时它只处理10个学生。理想情况下,该程序应能处理任意多个学生,但事先不知道要处理多少个学生,所使用的内存也不会比指定的学生分数所需的内存多。动态内存分配(dynamic memory allocation)就可以实现这个功能。可以在执行时创建足以容纳所需数据量的数组。
在程序的执行期间分配内存时,内存区域中的这个空间称为堆(heap),还有另一个内存区域,称为堆栈(stack),其中的空间分配给函数的参数和本地变量。在执行完该函数后,存储参数和本地变量的内存空间就会释放。堆中的内存是由程序员控制的。如本章后面所述,在分配堆上的内存时,由程序员跟踪所分配的内存何时不再需要,并释放这些空间,以便于以后重用它们。
第5章提到,可以利用变量指定数组的维,在运行期间创建数组。也可以在允许期间明确地分配内存。在运行时分配内存的最简单的标准库函数是 malloc() 。使用这个函数时,需要在程序中包含头文件<stdlib.h>。使用 malloc() 函数需指定要分配的内存字节数作为参数。这个函数返回所分配内存的第一个字节的地址。因为返回的是一个地址,所以这里必须使用指针。
动态内存分配的一个例子如下:
int *pNumber = (int*)malloc(100);
这条语句请求100个字节的内存,并把这个内存块的地址赋予 pNumber ,只要不修改它,任何时间使用这个变量 pNumber,它都会指向所分配的 100 个字节的第一个 int 的位置。这个内存块能保存25个 int 值,每个 int 占4个字节。这个语句假定 int 需要4个字节,最好删除这个假定,而编写如下语句:
int *pNumber = (int*) malloc (25*sizeof(int));
现在 malloc() 的参数清晰地指定,应分配足以容纳 25 个 int 值的内存。
注意,类型转换 (int*) 将函数返回的地址转换成 int 类型的指针。这么做是因为 malloc() 是一般用途的函数,可为任何类型的数据分配内存。这个函数不知道要这个内存做什么用,所以它返回的是一个 void 类型的指针,写成 void*。类型 void* 的指针可以指向任意类型的数据,然而不能取消对 void 指针的引用,因为它指向未具体说明的对象。许多编译器会把 malloc() 返回的地址自动转换成赋值语句左边的指针类型,但加上显式类型转换指令是无害的。
注意:
只要可能,编译器就总是把赋予语句中右操作数的表达式值转换为左操作数中存储它所需的类型。
可以请求任意数量的字节,字节数仅受制于计算机中未用的内存以及 malloc() 的运用场合。如果因某种原因而不能分配请求的内存, malloc() 会返回一个 NULL 指针。这个指针等于0。最好先用 if 语句检查请求动态分配的内存是否已分配,再使用它。就如同金钱,没钱又想花费,会带来灾难性的后果。因此,应编写如下语句:
int *pNumber = (int*) malloc (25*sizeof(int));
if (!pNumber) {
// Code to deal with memory allocation failure ...处理内存分配失败的代码…
}
现在,至少可以显示一条信息,然后中止程序。这比允许程序继续执行,使之使用 NULL 地址存储数据导致崩溃要好得多。然而,在某些情况下,可以释放在别的地方使用的内存,以便程序有足够的内存继续执行下去。
在动态分配内存时,应该总是在不需要该内存时释放它们。堆上分配的内存会在程序结束时自动释放,但最好在使用完这些内存后立即释放,甚至是在退出程序之前,也应立即释放。在比较复杂的情况下,很容易出现内存泄漏。当动态分配了一些内存时,没有保留对它们的引用,就会出现内存泄漏,此时无法释放内存。这常常发生在循环内部,由于没有释放不再需要的内存,程序会在每次循环迭代时使用越来越多的内存,最终占用所有内存。
当然,要释放动态分配的内存,必须能访问引用内存块的地址。要释放动态分配的内存,而该内存的地址存储在 pNumber 指针中,可以使用下面的语句:
free(pNumber);
pNumber = NULL;
free()函数的形参是void *类型,所有指针类型都可以自动转换为这个类型,所以可以把任意类型的指针作为参数传送给这个函数。只要pNumber包含分配内存时返回的地址,就会释放所分配的整个内存块,以备以后使用。在指针指向的内存释放后,应总是把指针设置为NULL.
警告:
在释放指针指向的堆内存时,必须确保它不被另一个地址覆盖。
如果给 free() 函数传送一个空指针,该函数就什么也不做。应避免两次释放相同的内存区域,因为在这种情况下, free() 函数的操作是不确定的,因此也就无法预料。如果多个指针变量引用已分配的内存,就有可能两次释放相同的内存,所以要特别小心。
在<stdlib.h>头文件中声明的 calloc() 函数与 malloc() 函数相比有两个优点。第一,它把内存分配为给定大小的数组,第二,它初始化了所分配的内存,所有的位都是0。calloc() 函数需要两个参数:数组的元素个数和数组元素占用的字节数,这两个参数的类型都是 size_t 。该函数也不知道数组元素的类型,所以所分配区域的地址返回为void*类型。
下面的语句使用 calloc() 为包含75个int元素的数组分配内存:
int *pNumber = (int*) calloc (75, sizeof (int));
如果不能分配所请求的内存,返回值就是 NULL ,也可以检查分配内存的结果,这,非常类似于 malloc(),但calloc()分配的内存区域都会初始化为0。当然,可以让编译器执行类型转换:
int *pNumber = calloc (75, sizeof (int));
后面的代码省略了这个类型转换。
将程序7.11改为使用 calloc() 代替 malloc() 来分配需要的内存,只需要修改一条语句。.其他代码不变:
realloc() 函数可以重用或扩展以前用 malloc() 或 calloc() (或者realloc())分配的内存。realloc() 函数需要两个参数:一个是包含地址的指针,该地址以前由malloc(), calloc()或 realloc() 返回,另一个是要分配的新内存的字节数。
realloc() 函数分配第二个参数指定的内存量,并把第一个指针参数引用的、以前分配的内存内容传递到新分配的内存中,且所传递的内容量是新旧内存区域中较小的那一个。该函数返回一个指向新内存的 void* 指针,如果函数因某种原因失败,就返回 NULL。新扩展的内存可以大于或小于原内存。如果 realloc() 的第一个参数是 NULL,就分配第二个参数指定的新内存,所以此时它类似于 malloc() 。如果第一个参数不是NULL,但不指向以前分配的内存,或者指向已释放的内存,结果就是不确定的。
这个操作最重要的特性是 realloc() 保存了原内存区域的内容,且保存的量是新旧内存区域中较小的那一个。如果新内存区域大于旧内存区域,新增的内存就不初始化,而是包含垃圾值。
下面是使用动态分配的内存的基本规则:
- 避免分配大量的小内存块。分配堆上的内存有一些系统开销,所以分配许多小的内存块比分配几个大内存块的系统开销大。
- 仅在需要时分配内存。只要使用完堆上的内存块,就释放它。
- 总是确保释放已分配的内存。在编写分配内存的代码时,就要确定在代码的什么地方释放内存。
- 在释放内存之前,确保不会无意中覆盖堆上已分配的内存的地址,否则程序就会出现内存泄漏。在循环中分配内存时,要特别小心。
注意:
使用realloc()分配内存失败后调用free(),编译器可能会发出一个警告。这里调用free()是有效的,因为内存是以前分配的,但编译器不知道。
前面使用 char 类型的数组元素存储字符串,也可以使用 char 类型的指针变量引用字符串。这个方法在处理字符串时非常灵活。下面的语句声明了一个 char 类型的指针变量:
char *pstring = NULL;
注意,指针只是一个存储另一个内存位置的地址的变量。前面只创建了指针,没有指定一个存储字符串的地方。要存储字符串,需要分配一些内存,在指针变量中存储其地址。在这种情况下,动态内存分配功能非常有效,例如:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void) {
const size_t BUF_SIZE = 100; // Input buffer size
char buffer[BUF_SIZE]; // A 100 byte input buffer
scanf_s("%s", buffer, BUF_SIZE); // Read a string
// Allocate space for the string
size_t length = strnlen(buffer, BUF_SIZE) + 1;
char *pstring = malloc(length);
if (!pstring) {
printf("Memory allocation failed.\n");
return 1;
}
strcpy_s(pstring, length, buffer); // copy string to new memory
printf("%s", pstring);
free(pstring);
pstring = NULL;
}
这段代码把一个字符串读入一个 char 数组中,给读入的字符串分配堆上的内存,再将字符串复制到新内存中。把字符串复制到 pString 引用的内存中,就允许重用 buffer ,来读取更多的数据。显然,下一步是读取另一个字符串,那么,如何处理任意长度的多个字符串?
当然,处理多个字符串时,可以在堆上使用指针数组存储对字符串的引用。假定从键盘上读取10个字符串,并存储它们。可以创建一个指针数组,存储字符串的位置:
char *ps [10] = { NULL };
这条语句声明了一个数组 ps,它包含10个 char 类型的元素, ps 中的每个元素都可以存储字符串的地址。第5章提到,如果在数组初始化列表中提供的初始值个数少于数组的元素个数,剩下的元素就初始化为0,因此,上述语句的初始化列表中只有一个值 NUL L,它将任意大小的指针数组中的所有元素都初始化为 NULL 。
下面使用这个指针数组:
#define STR_COUNT 10 // Number of string pointers
const size_t BUF_SIZE = 100; // Input buffer size
char buffer [BUF_SIZE]; // A 100 byte input buffer
char *ps [STR_COUNT] ={NULL}; // Array of pointers11
size_t str_size = 0;
for (size_t i =o ; i< STR_COUNT ; ++i)
{
scanf_s ("%s", buffer, BUF_SIZE); // Read a string
str_size = strnlen_s (buffer, BUF_SIZE) + 1; // Bytes required
ps[i] = malloc(str_size); // Allocate space for the string
if (!ps[i]) return 1; // Allocation failed so end
strcpy_s(ps[i], str_size, buffer); // Copy string to new memory
}
// Do things with the strings. .
// Release the heap memory
for (size_t i =o; i< STR_COUNT ; ++i)
{
free (ps [i]);
ps [i] =NULL;
}
ps 数组的每个元素都保存从键盘读取的一个字符串的地址。该数组有 STR_COUNT 个元素。注意在初始化数组时,不能使用变量指定数组的维数,即使把这个变量声明为 const 也不行。用变量指定数组的维数,该数组就是变长的,不允许初始化它,但总是可以在创建数组后,在循环中设置元素的值。在编译代码之前,符号用它表示的内容替代,所以在编译时, ps 的维数是 10。
字符串在 for 循环中输入。字符串读入 buffer 后,就使用 malloc() 在堆上分配足够的内存,来存储字符串。malloc()返回的指针存储在 ps 数组的一个元素中。接着,把 buffer 中的字符串复制到为它分配的内存中,使 buffer 可用于读取下一个字符串。最后得到一个字符串数组,其中的每个字符串都占用它需要的字节数,这是非常高效的。但如果不知道要输入多少个字符串,该怎么办?下面通过一个示例说明如何处理这种情形。
这是程序6.10的修订版,它在某个随意的散文中查找每个单词出现的次数。这个版本在堆上分配内存,来存储散文、单词和单词数。因为代码很多,所以内存分配函数中.省略了NULL指针的检查,以减少代码行数,但读者应总是包含它们。下面是代码:
前面的例子使用了指针记号,但不一定要这么做。对于指向一块堆内存的指针变量,还可以使用数组记号来存储相同类型的几个数据项。例如,下面的语句分配了一些堆内存:
int count = 100;
double* data = calloc (count, sizeof (double));
这段代码分配了足够的内存来保存 double 类型的 100 个值,并把它们初始化为 0.0 这个内存的地址存储在 data 中。可以访问这个内存,就好像 data 是一个包含 100 个 double 元素的数组。例如,可以利用循环在内存中设置不同的值:
for (int i=0; i < count ; ++i)
data [i] = (double) (i + 1)*(i + 1);
这段代码把值设置为 1.0、4.0、9.0 等。它只使用了指针名和放在方括号中的索引值,就好像在使用数组一样。不要忘了, data 是一个指针,而不是数组。表达式sizeof(data)得到存储地址所需的字节数,在我的系统中是 8,如果 data 是一个数组,该表达式就得到数组占用的字节数,即800。
可以重写程序7.13中的for循环,使用数组记号检查最新找到的单词是否已存在:
for(int i =o ; i < word count ; ++i)
{
if (strcmp (pwords [i], pWord) ==0)
{
++pnword [i];
new word = false;
break;
}
}
假定 pWords 是 char* 型数组的起始地址,则表达式 pWords[i] 访问第 i 个元素。因此这个表达式访问第 i 个单词,与最初的表达式 (pWords +i) 完全相同。同样, pnWord[i]与(pnWord + i)等价。数组记号比指针记号更容易理解,所以应尽可能使用它。下面的示例就对堆内存使用数组记号。
前面介绍了C语言中一个比较难的部分,现在运用学过的内容编写一个应用程序尤,其是指针记号。本节将依循惯例,先分析、设计,然后一步步编写代码。这是本章最后一个程序。
要处理的问题是用一些新的特性重写第3章的计算器程序,但这次要使用指针。主要改进如下:
- 允许使用有符号的小数,包含带-或+符号的小数和有符号的整数。
- 允许表达式组合多运算式,如2.5+3.7-6/6.
- 添加运算符^,计算幂,因此2^3会得到8
- 允许使用前一个运算的结果。如果前一个运算的结果是2.5,那么=2+7会得到12,任何以赋值运算符开头的输入行都自动假设左操作数是前一个运算的结果。不考虑运算符的优先级,只简单地从左到右计算输入的表达式,将每个运算符应用于前一个结果和右操作数。所以下面的表达式: 1+ 23-4*-5 会以如下方式计算: ((1+2)3-4)(-5)
本章涵盖了许多基础知识,详细探讨了指针。读者现在应该了解指针和数组(一维和多维数组)间的关系了,并掌握了它们的用法。本章介绍了动态分配内存的函数malloc()、calloc()和realloc(),它们给程序提供了足够的内存,以执行数据处理。函数free()用来释放先前由malloc()、 calloc()和realloc()分配的内存。读者应该很清楚如何给字符串使用指针,如何使用指针数组,如何使用指针记号。
本章讨论的主题是本书以后许多章书的基础,对编写C程序是很有帮助的,所以在进入下一章之前,一定要熟练掌握这些内容。
注意本章许多示例的代码都很混乱。Main0中的语句数非常大,很难理解代码,程序7.15尤其如此,其中的main()超过了100行代码。这不是好的C编程方式。C程序应由许多短函数构成,每个函数都执行定义好的操作。而程序 7.15 的逻辑可以自然地分成几个不同的、定义好的、相互独立的操作。其中还有一些重复的代码,例如,提取左操作数的代码与提取右操作数的代码就几乎完全相同。第8章将使用函数组织程序,对函数有了更多的了解后,就可以更好地实现程序7.15了。