Beginning C , Fifth Edition 第6章:字符串和文本的应用
本章将探讨如何使用字符数组,以扩展数组知识。我们经常需要将文本字符串用作个实体,不过C语言没有提供字符串数据类型,而是使用char类型的数组元素存储字符串。本章将介绍如何创建和处理字符串变量,标准库函数如何简化字符串的处理。
本章的主要内容:
- 如何创建字符串变量
- 如何连接两个或多个字符串,形成一个字符串
- 如何比较字符串
- 如何使用字符串数组
- 哪些库函数能处理字符串,如何应用它们
字符串常量的例子非常常见。字符串常量是放在一对双引号中的一串字符或符号。一对双引号之间的任何内容都会被编译器视为字符串,包括特殊字符和嵌入的空格。每次使用print()显示信息时,就将该信息定义成字符串常量了。以下的语句是用这种方法使用字符串的例子:
printf ("This is a string.");
printf ("This is on\ntwo lines!");
printf ("For \" you write \\\".");
这3个字符串例子如图6-1所示。存储在内存中的字符码的十进制值显示在这些字符的下方。
第一个字符串是一系列字符后跟一个句号。printf()函数会把这个字符串输出为:
This is a string.
第二个字符串有一个换行符\n,所以字符串显示在两行上:
This is on
two lines!
·第三个字符串有点难以理解,但print()函数的输出很清楚:
For " you write \".
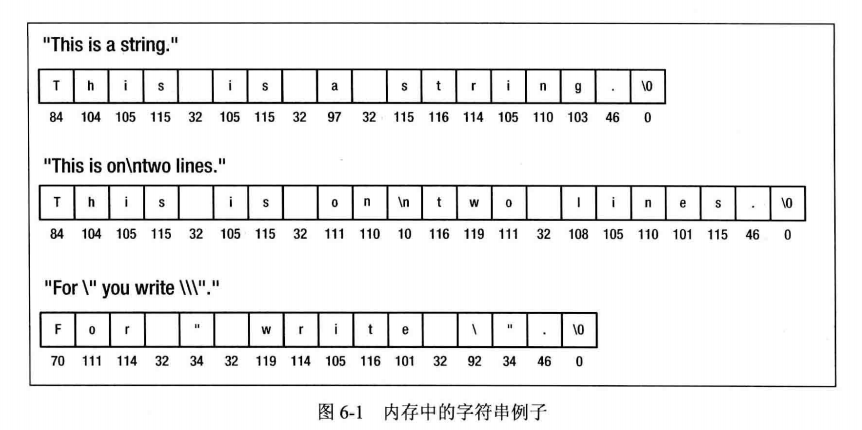 必须把字符串中的双引号写为转义序列",因为编译器会把双引号看作字符串的结尾。要在字符串中包含反斜杠,也必须使用转义序列\,因为字符串中的反斜杠总是表示转义序列的开头。
必须把字符串中的双引号写为转义序列",因为编译器会把双引号看作字符串的结尾。要在字符串中包含反斜杠,也必须使用转义序列\,因为字符串中的反斜杠总是表示转义序列的开头。
如图6-1所示,每个字符串的末尾都添加了代码值为0的特殊字符,这个字符称为空字符,写为\0。C中的字符串总是由\0字符结束,所以字符串的长度永远比字符串中的字符数多1。
注意
空字符不要和 NULL 混淆。空字符是字符串的终止符,而 NULL 是一个符号,表示不引用任何内容的内存地址。
可以自己将 \0 字符添加到字符串的结尾,但是这会使字符串的末尾有两个\0字符。下面的程序说明了空字符是如何运作的:
#include <stdio.h>
int main(void){
printf ("This is a \0 string.");
return 0;
}
编译并执行这个程序,会得到如下输出:
This is a
这可不是我们期望的结果:仅显示了字符串的第一部分。这个程序显示了前两个字符后就结束输出,是因为print()函数遇到第一个空字符 \0 时,就会停止输出。即使在字符串的末尾还有另一个 \0,也永远不会执行它。在遇到第一个 \0 时,就表示字符串结束了。
C 语言对变量存储字符串的语法没有特殊的规定,而且 C 根本就没有字符串变量,也没有处理字符串的特殊运算符。但这不成问题,因为标准库提供了许多函数来处理字符串,下面先看看如何创建表示字符串的变量。
如本章开头所述,可以使用 char 类型的数组保存字符串。这是字符串变量的最简单式。char数组变量的声明如下:
char saying[20];
这个变量可以存储一个至多包含19个字符的字符串,因为必须给终止字符提供一个数组元素。当然也可以使用这个数组存储20个字符,那就不是一个字符串了。
警告
声明存储字符串的数组时,其大小至少要比所存储的字符数多1,因为编译器会自动在字符串常量的末尾添加 \0。
也可以用以下的声明初始化前面的字符串变量:
char saying[] ="This is a string.";
这里没有明确定义这个数组的大小。编译器会指定一个足以容纳这个初始化字符串常量的数值。在这个例子中它是18,其中17个元素用于存储字符串中的字符,再加上一个额外的终止字符 \0。当然可以指定这个数值,但是如果让编译器指定,可以确保它一定正确。
也可以用一个字符串初始化char类型数组的部分元素,例如:
char saying[40] ="To be";
这里编译器会使用指定字符串的字符初始化从str0]到str[4]的前5个元素,而str[5]含有空字符\0。当然,数组的所有40个元素都会被分配空间,可以以任意方式使用。初始化一个char数组,将它声明为常量,是处理标准信息的好方法:
const char message[] ="This is a string.";
将 message 声明成常量,它就不会在程序中被显式更改。只要试图更改它,编译器都会产生错误信息。当标准信息在程序中的许多地方使用时,这种定义标准信息的方法特别有用。它可以防止在程序的其他部分意外地修改这种常量。当然,假使必须改变这条信息,就不应将它指定为 const。
要引用存储在数组中的字符串时,只需使用数组名即可。例如,如果要用print()函数输出存储在 message 中的字符串,可以编写:
printf ("The message is:%s",message);
这个 %s 说明符用于输出一个用空字符终止的字符串。函数printf()会在第一个参数的 %s 位置,输出 message 数组中连续的字符,直到遇到 \0 字符为止。当然, char数组的执行方式与其他类型的数组一样,所以可以用相同的方式使用它。字符串处理函数唯需要特别考虑的是 \0 字符,所以从外表看来,包含字符串的数组没有什么特别的。
使用char数组存储许多不同的字符串时,必须用足以容纳要存储的最大字符串长度来声明数组的大小。在大多数情况下,一般的字符串都会小于这个最大值,所以确定字符串的长度是很重要的,特别是要给字符串添加更多的字符。下面用一个例子来说明:
#include <stdio.h>
int main(void) {
char str1[] = "To be or not to be";
char str2[] = ",that is the question";
unsigned int count = 0;
while (str1[count] != '\0') {
++count;
}
printf("The length of the string \"%s\" is %d characters.\n", str1, count);
count = 0;
while (str2[count] != '\0') {
++count;
}
printf("The length of the string \"%s\" is %d characters.\n", str2, count);
return 0;
}
可以使用char类型的二维数组存储字符串,数组的每一行都用来存储一个字符串。这样,就可以存储一整串字符串,通过一个变量名来引用它们,例如:
char sayings [3][32] = {
"Manners markth man.",
"Many hands make lightwork.",
"Manners markth man."
}
这条语句创建了一个数组,它包含3行,每行32个字符。括号中的字符串按顺序指定数组的3行sayings[0]、 sayings[1]和sayings[3]。注意,不需要用括号将每个字符串括起来。编译器能推断出每个字符串初始化数组的一行。第一维指定数组可以包含的字符串个数,第二维指定为32,刚好能容纳最长的字符串(包含\0终止字符)。
在引用数组的元素时,例如sayings[i][j],第一个索引i指定数组中的行,第二个索引j指定该行中的一个字符。要引用数组中包含一个字符串的一整行,只需在方括号中包含一个索引值。例如sayings[1]引用数组的第二个字符串, “Many hands make lightwork."。
在字符串数组中,必须指定第二维的大小,也可以让编译器计算数组有多少个字符串。上述定义可以写为:
char sayings [][32] = {
"Manners markth man.",
"Many hands make lightwork.",
"Manners markth man."
}
因为有3个初始字符串,编译器会将数组的第一维大小指定为3。当然,还必须确保第二维的空间足以容纳最长的字符串,包含终止字符。
上例说明了确定字符串长度的代码,但其实并不需要编写这样的代码。标准库提供了一个执行该操作的函数,和许多处理字符串的其他函数。要使用它们,必须把string.h 头文件包含在源文件中。
后面面向任务的章节主要介绍C11标准引入的新字符串函数,它们比以前习惯使用的传统函数更安全、更健壮,它们提供了更强大的保护,可以防止出现缓存溢出等错误。但是,这个保护依赖仔细而正确的编码。
标准库提供的字符串处理函数默认集合并不安全。它们使代码包含错误的可能性很大,有时这些错误很难查找。一个较大的问题是在网络环境下使用时,它们允许恶意代码破坏程序。这些问题发生的主要原因是,无法验证数组有足够的空间执行操作。因此,C11标准包含字符串处理函数的可选版本,它们更安全、更不容易出错,因为它们会检查数组的维数,确保它们足够大。编写安全、不易出错的代码非常重要,所以这里主要介绍对数组进行边界检查的可选字符串处理函数。在我看来,任何遵循C11的编译器都应实现这些可选的字符串函数。所有的可选函数名都以s结尾。
很容易确定C编译器附带的标准库是否支持这些可选函数。只需要编译并执行如下代码:
#include <stdio.h>
int main(void) {
#if defined __STDC_LIB_EXT1__
printf("P1\n");
#else
printf("P2\n");
#endif
return 0;
}
根据C11标准实现可选函数的编译器,会定义 STDC_LIB_EXT1 符号。这段代码使用预处理器指令,根据是否定义了 STDC_LIB_EXT1 符号,插入两个printf()语句中的一个。如果定义了这个符号,代码就输出消息:
P1
如果没有定义 STDC_LIB_EXT1 符号,代码就输出消息:
P2
这里使用的预处理器指令(它们是以#开头的代码行)采用与if语句相同的执行方式。第13章将详细介绍预处理器指令。
要使用string.h中的可选函数,必须在string.h的include语句之前,在源文件中定义 STDC_LIB_EXT1 符号,来表示值1,如下所示: #define STDC_LIB_EXT1 1// Make optional versions of functions available
#define __STDC_LIB_EXT1__ 1// Make optional versions of functions available
#include <string.h>
如果没有把这个符号定义为1,就只能使用字符串处理函数的标准集合。为什么需要这个精巧的机制,才能使用可选函数?原因是它不会中断推出C11标准之前编写的旧代码。显然,旧代码可能使用了一个或多个新函数名。尤其是,许多程序员以前都实现了自己的、更安全的字符串处理函数,这样就很容易与C11库产生名称冲突。出现这种冲突时,把 STDC_LIB_EXT1 定义为0,禁止使用可选函数,旧代码就可以用C11编译器编译了。
strnlen_s()函数返回字符串的长度,它需要两个参数:字符串的地址(这是一维char数组的数组名)和数组的大小。知道数组的大小,若字符串没有结尾的\0字符,函数就可以避免访问最后一个元素后面的内存。
该函数把字符串的长度返回为一个size_t类型的整数值。如果第一个参数是NULL,就返回0。如果在第二个参数值的元素个数中,第一个参数指定的数组不包含\0字符,就返回第二个参数值,作为字符串的长度。
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <string.h>
int main(void) {
char s[] = "test";
printf("test:%zu", strnlen(s, sizeof(s)));
return 0;
}
注意
确定字符串长度的标准函数是strlen(),它只把字符串的地址作为参数。若字符串没有10,这个函数会越过字符串的末尾。
strcpy_s()函数可以把一个字符串变量的内容赋予另一个字符串。它的第一个参数指定复制目标,第二个参数是一个整数,指定第一个参数的大小,第三个参数是源字符串。指定目标字符串的长度,可以使函数避免覆盖目标字符串中最后一个字符后面的内存。如果源字符串比目标字符串长,就会发生这种情形。如果一切正常,该函数就返回0,否则就返回非0整数值。下面是一个示例:
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <string.h>
int main(void) {
char s[] = "test";
char s2[10];
unsigned int max = 3;
strncpy_s(s2, sizeof(s2), s,3);
printf("tes:%s.", s2);
printf("test:%zu", strnlen(s2, sizeof(s2)));
return 0;
}
strncpy_s() 函数可以把源字符串的一部分复制到目标字符串中。在strcpy_s()函数名中添加n表示,可以至多复制指定的n个字符。前三个参数与strcpy_s()相同,第四个参数指定从第三个参数指定的源字符串中复制的最大字符数。如果在复制指定的最大字符数之前,在源字符串中找到了\0,复制就停止,并把\0添加到目标字符串的末尾。
连接是把一个字符串连接到另一个字符串的尾部,这是很常见的需求。例如,把两个或多个字符串合成为一条信息。在程序中,将错误信息定义为几个基本的文本字符串,然后给它们添加另一个字符串,使之变成针对某个错误的信息。
把一个字符串复制到另一个字符串的末尾时,需要确保操作是否安全的两个方面:第一,目标字符串的可用空间是否足够,不会覆盖其他数据,甚或代码;第二,连接得到的字符串末尾有、0字符。string.h中的可选函数strcat_s()满足这些要求。
strcat_s()函数需要三个参数:要添加新字符串的字符串地址,第一个参数可以存储的最大字符串长度,要添加到第一个参数中的字符串地址。该函数把一个整数错误码返回为erno_t类型的值,它是一个取决于编译器的整数类型。
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <string.h>
int main(void) {
char str1[50] = "to be, or not to be,";
char str2[] = "that is question.";
int retval = strcat_s(str1, sizeof(str1), str2);
printf("str1:%s\n", str1);
char s[] = "test";
char s2[10];
unsigned int max = 3;
strncpy_s(s2, sizeof(s2), s,3);
printf("tes:%s.", s2);
printf("test:%zu", strnlen(s2, sizeof(s2)));
return 0;
}
字符串strl和strl连接在一起,所以这个代码段使用strcat s()把str2追加到strl上。该操作把str2复制到strl的末尾,覆盖strl中的0,再在最后添加一个1。如果一切正常,strcat s)就返回0。如果strl不够大,不能追加str2,或者有其他条件禁止该操作正确执行,返回值就非0
与strncpy_s()一样,可选函数strncat_s()把一个字符串的一部分连接到另一个字符串上。它也有一个额外的参数,指定要连接的最大字符数。下面是其工作方式:
警告
不能把字符串连接到不包含字符串的数组中。如果希望使用strcats()或strncat_s()把preamble复制到joke中,就需要把joke初始化为空字符串。数组的维数在运行期间确定时,编译器就不允许在声明语句中初始化数组。要把joke初始化为空数组,可以使用赋值语句在joke[0]中存储
注意
终止程序时返回的任何非0值都表示异常。给异常使用不同的非0值,可以表示代"码中出现了异常。
字符串库提供的函数还可以比较字符串,确定一个字符串是大于还是小于另一个字符串。字符串使用“大于”和“小于”这样的术语听起来有点奇怪,但是其结果相当简单。两个字符串的比较是基于它们的字符码,如图6-2所示,图中的字符码显示为十六进制数。
如果两个字符串是相同的,它们就是相等的。要确定第一个字符串是小于还是大于第二个字符串,应比较两个字符串中第一对不同的字符。例如,如果第一个字符串中某字符的字符码小于第二个字符串中的对应字符,第一个字符串就小于第二个字符串。以字母次序安排字符串时,这种比较机制一般符合我们的预期。
头文件<string.h>声明了几个字符串搜索函数,但是在探讨它们之前,先了解下一章的主题-指针,这里需要这些基础知识,以理解如何使用字符串搜索函数。
每一个变量都有一个内存位置,每一个内存位置都定义了可使用 & 运算符访问的地址,它表示了在内存中的一个地址。
我们将内存中字节的编号称为地址(Address)或指针(Pointer)。地址从 0 开始依次增加,对于 32 位环境,程序能够使用的内存为 4GB,最小的地址为 0,最大的地址为 0XFFFFFFFF。
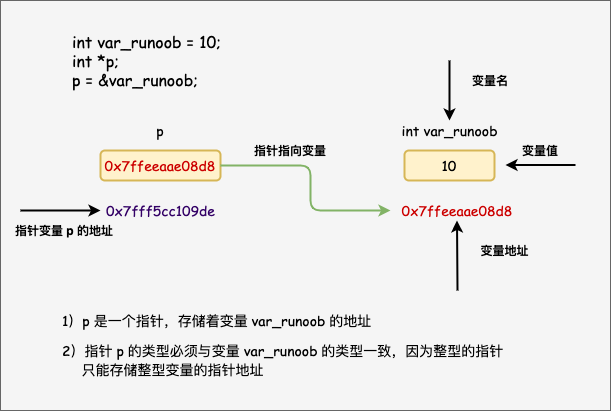
数据在内存中的地址也称为指针,如果一个变量存储了一份数据的指针,我们就称它为指针变量。
在 C 语言中,允许用一个变量来存放指针,这种变量称为指针变量。指针变量的值就是某份数据的地址,这样的一份数据可以是数组、字符串、函数,也可以是另外的一个普通变量或指针变量。
1、定义指针变量
定义指针变量与定义普通变量非常类似,不过要在变量名前面加星号*,格式为:
datatype *name;
datatype 表示该指针变量所指向的数据的类型,* 表示这是一个指针变量。
2、寻址运算符 &
在变量前加上寻让运算符 &,可以获得变量在内存中的地址。
结合 定义指针变量 和 寻址运算符 即可完成对指针变量的定义和赋值。
int a = 100;
int *p_a = &a;
在定义指针变量 p_a 的同时对它进行初始化,并将变量 a 的地址赋予它,此时 p_a 就指向了 a。值得注意的是,p_a 作为一个变量,本身有自己的的一个地址,p_a 变量的值是 a 的地址。
注意
* 是一个特殊符号,在声明变量时,在变量名前加 * ,可以表明一个变量是指针变量,后边可以像使用普通变量一样直接用变量名来使用指针变量。也就是说,定义指针变量时必须带 *,给指针变量赋值时不能带 *。
3、通过指针变量取得数据
指针变量存储了数据的地址,通过指针变量能够获得该地址上的数据,格式为:
*p_a;
此时:* 是取消引用运算符,其作用是访问指针指定的地址种存储的数据。 p_a 是一个 指针变量,通过 *p_a 来取得 p_a 存储的地址上的数据,例如:
#include <stdio.h>
int main(){
int a = 15;
int *p_a = &a;
printf("%d, %d\n", a, *p_a); //两种方式都可以输出a的值
return 0;
}
普通变量和指针变量都是地址的助记符,程序被编译和链接后,a、p_a 被替换成相应的地址。虽然通过 *p_a 和 a 获取到的数据一样,但它们的运行过程稍有不同:a 只需要一次运算就能够取得数据,而 *p_a 要经过两次运算,多了一层“间接”。
也就是说,使用指针是间接获取数据,使用变量名是直接获取数据,前者比后者的代价要高。
指针除了可以获取内存上的数据,也可以修改内存上的数据,例如:
#include <stdio.h>
int main(){
int a = 15, b = 99, c = 222;
int *p = &a; //定义指针变量
*p = b; //通过指针变量修改内存上的数据
c = *p; //通过指针变量获取内存上的数据
printf("%d, %d, %d, %d\n", a, b, c, *p);
return 0;
}
运行结果:
99, 99, 99, 99
特殊符合 * 在不同的场景下有不同的作用:* 可以用在指针变量的定义中,表明这是一个指针变量,以和普通变量区分开;使用指针变量时在前面加表示获取指针指向的数据,或者说表示的是指针指向的数据本身。 也就是说,定义指针变量时的和使用指针变量时的*意义完全不同。
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <string.h>
int main(void) {
int Number = 25;
int *ppNumber = &Number;//Number 是一个变量,用来存放整数,需要在前面加&来获得它的地址;
printf("Number 变量的地址: %p\n", ppNumber);
printf("Number 变量的值: %d\n", *ppNumber);
}
不同数据类型的指针
int *ip; /* 一个整型的指针 */
double *dp; /* 一个 double 型的指针 */
float *fp; /* 一个浮点型的指针 */
char *ch; /* 一个字符型的指针 */
所有实际数据类型,不管是整型、浮点型、字符型,还是其他的数据类型,对应指针的值的类型都是一样的,都是一个代表内存地址的长的十六进制数。
不同数据类型的指针之间唯一的不同是,指针所指向的变量或常量的数据类型不同。
函数strchr()在字符串中搜索给定的字符。它的第一个参数是要搜索的字符串(是char数组的地址),第二个参数是要查找的字符。这个函数会从字符串的开头开始搜索,返回在字符串中找到的第一个给定字符的地址。这是一个在内存中的地址,其类型为char*,表示"char的指针”。所以要存储这个返回值,必须创建一个能存储字符地址的变量。如果没有找到给定的字符,函数就会返回NULL,它相当于0,表示这个指针没有指向任何对象。
函数 strchr() 的用法如下:
char str[] = "The quick brown fox";
char ch ='q';
char *pGot_char = NULL;
pGot_char = strchr(str, ch);
strchr() 函数的第一个参数是要查找的字符的地址,这里它是str的第一个元素。第二个参数是已找到的字符,这里它是char类型的ch, strchr() 函数希望其第二个参数是int类型,所以编译器在将它传给函数之前,先把ch的值转换为int类型。
int ch = 'q';
函数经常要求将字符作为int类型参数传入,因为int类型比char类型更易用。而表·示文件尾的EOF字符是一个负整数,如果char是一个无符号类型,就不能表示负整数。图6-4说明了使用strchr() 函数搜索的结果。
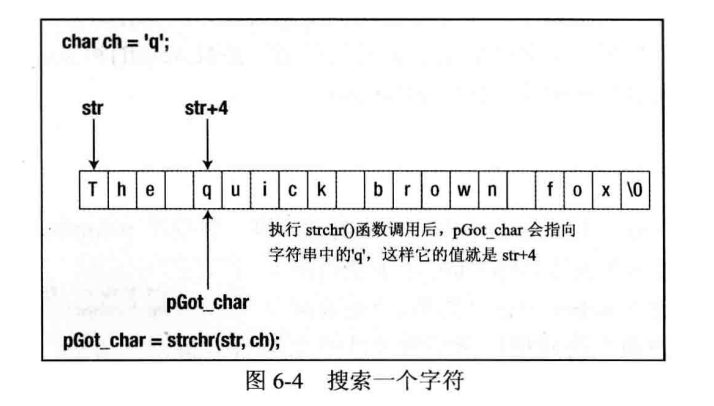
在字符串中,第一个字符的地址是数组名称 str 指定的。‘q’是字符串中的第5个字符,所以它的地址是str+4,与第一个字符偏移4字节。因此变量 pGot_char 将含有地址str+4.
在表达式中使用变量名称 pGot_char 可以访问地址。如果要访问存储该地址中的字符,就必须取消对这个指针的引用。为此,在指针变量名之前使用取消引用运算符*,例如:
printf("pGot_char:%c\n", *pGot_char);
下一章将详细介绍取消引用运算符。当然,我们要查找的字符不一定在字符串中,所以不要试图取消对NULL指针的引用,如果尝试取消NULL指针的引用,程序会崩溃。只要使用if语句就可以避免这种情况,如下:
if (pGot_char)
printf("pGot_char:%c\n", *pGot_char);
NULL指针值转换为bool值false,非NULL指针值转换为true。如果 pGot_char 是NULL, if表达式就是false,不调用printf()语句。现在,只要变量pGot char不是NULL,就执行printf()语句。
使用下面的代码很容易搜索一个字符的多个实例:
char str11[] = "Peter piper picked a peck of pickled pepper.";
char ch11 = 'p';
char *pGot_char11 = str11;
int count =0;
while (pGot_char11 = strchr(pGot_char11, ch11)) {
++count;
++pGot_char11;
}
printf ("The character '%c' was found %d times in the following string:\n\"%s\"\n", ch11, count, str11);
pGot_char 指针用字符串str的地址初始化。搜索在while循环条件中进行。调用 strchr() 函数,开始在 pGot_char 的地址中搜索ch,最初该地址是开始保存 str 的地方。返回值存储回pGot_char 中,所以这个值确定循环是否继续。如果找到了ch,就给 pGot_char 赋予在字符串中找到ch的地址,循环继续执行。在循环体中,递增找到字符的次数,还要递增 pGot_char ,使它包含的地址引用找到 ch 的位置后面的字符。接着下一个循环迭代从这个新地址开始搜索。strchr() 返回NULL时,循环结束。
函数 strrchr() 基本上类似于 strchr() 的操作,其两个参数是相同的,第一个是要搜索的字符串的地址,第二个参数是要查找的字符。但 strrchr() 从字符串的末尾开始查找字符。因此,它返回字符串中的最后一个给定字符的地址,如果找不到给定字符,就返回NULL.
strstr() 函数是所有搜索函数中最有用的函数,它查找一个字符串中的子字符串,返回找到的第一个子字符串的位置指针。如果找不到匹配的子字符串,就返回NULL,所以如果返回值不是NULL,就说明这个函数找到了所需的子字符串。这个函数的第一个参数是要搜索的字符串,第二个参数是要查找的子字符串。下面有一个使用 strstr() 函数的例子:
char text[] = "Every dog has his day";
char word[] ="dog";
char *pFound = NULL;
pFound = strstr(text, word);
这些语句在字符串 text 中寻找 word 中包含的子字符串。字符串"dog"出现在text的第7个位置,所以pFound设定为地址text+6,这个搜索是区分大小写的,所以如果在text字符串中查找的是"Dog”,就找不到匹配的子字符串。
标记是字符串中用某些预定义界定符界定的一个字符序列。例如,把这个句子看作,一个字符串,则单词用空格、逗号和句点来界定。
把句子分解为单词称为语汇单元化(tokenizing),标准库提供了 strtok() 函数,来单元化字符串。它需要两个参数:要单元化的字符串,和包含所有可能的界定符的字符串。也有一个可选的单元化函数strtok_s(),它使用起来比标准函数更安全,所以这里会描述其工作方式。因为它是一个可选的标准函数,所以需要把_STDC_WANT_LIB_EXT1__ 符号定义为1,才能使用它。
strtok_s() 的工作方式有点复杂,因为它允许多次调用函数,在单个字符串中连续查找界定符。这里先解释必须提供的参数,再解释函数的操作。
strtok_s() 函数需要4个参数:
- str:要单元化的字符串的地址。执行第一次单元化后,对同一个字符串执行第二次和后续的单元化操作时,这个参数就是NULL
- str-size:包含数组长度的整数变量的地址,在该数组中存储了第一个参数。在当前搜索后,函数会更新这个参数,使之存储字符串中要单元化的剩余字符数。
- delimiters:包含所有可能界定符的字符串的地址。
- pptr:指向char*型变量的指针,函数在该变量中存储信息,允许在找到第一个标记后,继续搜索标记。
注意
指向char型变量的指针是char**类型,详见下一章。当然,对于char型的变量ptr,指向它的指针是&ptr.
该函数返回char*类型的指针,指向标记的第一个字符,如果没有找到标记,就指向NULL,这表示字符串为空,或者只包含界定符。搜索多个标记时, strtok_s() 的操作如下:
(1)在第一次调用函数时,若str不是NULL,就搜索str,找到第一个不是界定符的字符。如果没有找到该字符,就说明字符串中没有标记,函数就返回NULL。如果找到了非界定符,函数就在后续字符中搜索界定符。找到界定符后,就用\0替代它,终止标记,然后再次调用函数,把NULL作为第一个参数,来查找另一个标记。
(2)在搜索给定字符串的第二次和后续调用中,第一个参数必须是NULL,第二和第四个参数必须是第一次函数调用时使用的相同参数。如果知道自己在做什么,就可以提供不同的delimiters字符串参数。函数从str中插入上一个\0的位置开始搜索非界定符如果没有找到该字符,就返回NULL,如果找到了,就搜索str中的后续字符,查找delimiters中的界定符。如果找到了界定符,就用 替代它,终止标记。然后再次调用限数,把NULL作为第一个参数,来查找另一个标记。
如果仍不明白strtok_s() 的操作,可以看看下面的示例。但要使用它处理从键盘输入·的文本,需要一种读取一串字符的方式。stdio.h中的gets_s()就可以实现该功能。这是一个可选函数,因为它替代了gets(), gets()现在是一个废弃的函数,不应使用它。
gets_s()函数需要两个参数,第一个是数组str的地址,该数组包含要存储的字符,第二个参数是数组的大小。该函数至多从键盘上读取比数组长度小1个字符,包括空格。如果在str中存储了最大字符数后,又输入了更多的字符,就会舍弃它们。按下回车键会终止输入。函数在读取的最后一个字符后面添加\0。如果只按下回车键,而没有输入字符, str[0]就设置为10。如果一切正常, gets_s()就返回str,否则返回NULL。下面的示例会演示其工作方式,它单元化了输入的文本。
程序 6.7 有一个问题。每行输入通过按下回车键来终止,这会输入一个换行符,但gets_s()没有把它存储在输入数组中。这意味着,如果不在一行的末尾或下一行的开头添加空格,一行中的最后一个单词就会与下一行中的第一个单词连接起来,但它们都是独立的单词。这会使输入过程非常不自然。使用fgets()函数可以更好地实现输入过程,该函数在输入的字符串中存储换行符,来结束输入过程。这是一个很常用的输入函数,可以用于读取文件和读取键盘输入。文件输入和输出参见第12章。
fgets()函数需要3个参数:输入数组str的地址、要读取的最大学符数(通常是str的学符串长度)和输入源(对于键盘,它是stdin)。该函数至多读取第二个参数指定的字符数-1个字符,并追加\0。按下回车键会在str中存储n,这会结束输入操作,还存储一个0,来结束字符串。程序 6.7 的修订版本演示了这个函数。
如果需要检查字符串内部的内容,可以使用在头文件<ctype.h>(详见第3章)中声明,的标准库函数。这些都是非常灵活的分析函数,可以测试有什么样的字符。它们还独立于计算机上的字符码。表6-1中的函数可以测试各种不同的字符种类。
开发一个程序,从键盘上读取任意长度的一段文本,确定该文本中每个单词的出现频率(忽略大小写)。该段文本的长度不完全是任意的,因为我们要给程序中的数组大小指定一个限制,但可以使该数组存储任意大小的文本。