Beginning C , Fifth Edition 第5章:数组
我们经常需要在程序中存储某种类型的大量数据值。例如,如果编写一个程序,追踪一支篮球队的成绩,就要存储一个赛季的各场分数和各个球员的得分,然后输出某个球员的整季得分,或在赛事进行过程中计算出赛季的平均得分。我们可以利用前面所学的知识编写一个程序,为每个分数使用不同的变量。然而,如果一个赛季里有非常多的赛事,这会非常繁琐,因为有球赛的每个球员都需要许多变量。所有篮球分数的类型都相同,不同的是分值,但它们都是篮球赛的分数。理想情况下,应将这些分值组织在一个名称下,例如球员的名字,这样就不需要为每个数据项定义变量了。
本章将介绍如何在C程序中使用数组,然后探讨程序使用数组时,如何通过一个名称来引用一组数值。
本章的主要内容:
- 什么是数组
- 如何在程序中使用数组
- 数组如何使用内存
- 什么是多维数组
- 如何编写程序,计算帽子的尺寸
- 如何编写井字游戏
说明数组的概念及其作用的最好方法,是通过一个例子,来说明使用数组后程序会变得非常简单。这个例子将计算某班学生的平均分数。
非常麻烦
数组是一组数目固定、类型相同的数据项,数组中的数据项称为元素。数组中的元素都是int, long或其他类型。下面的数组声明非常类似于声明一个含有单一数值的正常变量,但要在名称后的方括号中放置一个数。
long numbers [10];
方括号中的数字定义了要存放在数组中的元素个数,称为数组维(array dimension)。数组有一个类型,它组合了元素的类型和数组中的元素个数。因此如果两个数组的元素个数相同、类型也相同,这两个数组的类型就相同。
存储在数组中的每个数据项都用相同的名称访问,在这个例子中,该名称就是 numbers。要选择某个元素,可以在数组名称后的方括号内使用索引值。索引值是从0开始的连续整数。0是第一个元素的索引值,前面numbers数组的元素索引值是0-9,索引值0表示第一个元素,索引值9表示最后一个元素。因此数组元素可表示为numbers[0]numbers[1]、numbers[2] ……numbers[9]。
如图5-1所示:
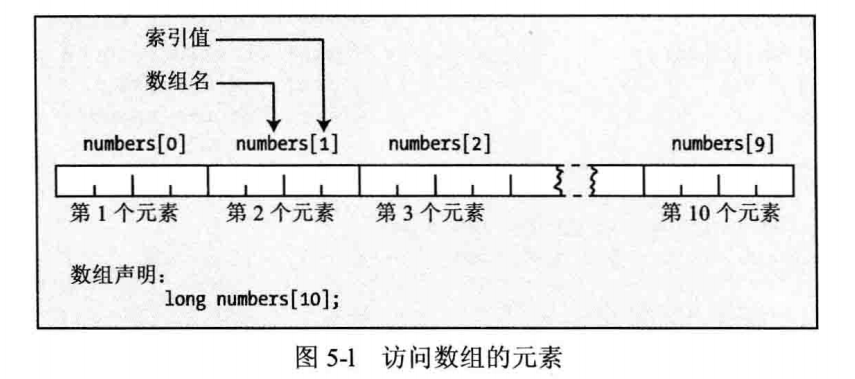 注意,索引值是从0开始,不是1,第一次使用数组时,这是一个常犯的错误,有时这称为off-by-one错误。在一个十元素数组中,最后一个元素的索引值是9,要访问数组中的第4个值,应使用表达式numbers[3]。数组元素的索引值是与第1个元素的偏移量。第1个元素的偏移量是0,第2个元素与第一个元素的偏移量是1,第3个元素与第一个元素的偏移量是2,依此类推。
注意,索引值是从0开始,不是1,第一次使用数组时,这是一个常犯的错误,有时这称为off-by-one错误。在一个十元素数组中,最后一个元素的索引值是9,要访问数组中的第4个值,应使用表达式numbers[3]。数组元素的索引值是与第1个元素的偏移量。第1个元素的偏移量是0,第2个元素与第一个元素的偏移量是1,第3个元素与第一个元素的偏移量是2,依此类推。
要访问numbers数组元素的值,也可以在数组名称后的方括号内放置表达式,该表达式的结果必须是一个整数,对应于一个可能的索引值。例如numbers[i-2]。如果i的值是3,就访问数组中的第2个元素numbers[1]。因此,有两种方法来指定索引值,以访问数组中的某个元素。其一,可以使用一个简单的整数,明确指定要访问的元素。其二,可以使用一个在执行程序期间计算的整数表达式。使用表达式的唯一限制是,它的结果必须是整数,该整数必须是对数组有效的索引值。
注意,如果在程序中使用的索引值超过了这个数组的合法范围,程序将不能正常运作。编译器检查不出这种错误,所以程序仍可以编译,但是执行是有问题的。在最好的情况下,是从某处提取了一个垃圾值,所以结果是错误的,且每次执行的结果都不会相同。在最糟的情况下,程序可能会覆盖重要的信息,且锁死计算机,需要重启计算机。有时,这对程序的影响比较微妙:程序有时能正常工作,有时不能,或者程序看起来工作正常,但结果是错误的,只是不明显。因此,一定要细心检查数组索引是否在合法范围内。
跟 Java 一样
#include <stdio.h>
int main(void) {
int grades[10];
unsigned int count = 10;
long sum = 0L;
float average = 0.0f;
printf("\nEnter the 10 grades:\n");
for (unsigned int i = 0; i < count; ++i) {
printf("%2u>", i + 1);
scanf("%d", &grades[i]);
sum += grades[i];
}
average = (float) sum / count;
printf("\nAverage of the ten grades entered is: %.2f\n", average);
return 0;
}
寻址运算符 & 输出其操作数的内存地址。前面使用了寻址运算符 &,它广泛用于scanf()函数。它放在存储输入的变量名称之前, scanf()函数就可以利用这个变量的地址,允许将键盘输入的数据存入变量。只把这个变量名称用作函数的参数,函数就可以使用变量存储的值。而把寻址运算符放在变量名称之前,函数就可以利用这个变量的地址,修改在这个变量中存储的值,其原因参见第8章。下面是一些地址的例子:
#include <stdio.h>
int main(void){
long a = 1L;
long b = 2L;
long c = 3L;
double d = 4.0;
double e = 5.0;
double f = 6.0;
printf("%u bytes.\n", sizeof(long));
printf("a:%p ;\nb:%p ;\nc:%p.\n", &a, &b, &c);
printf("%u bytes.\n", sizeof(double));
printf("d:%p ;\ne:%p ;\nf:%p.", &d, &e, &f);
}
这个程序的输出如下:
4 bytes.
a:000000000064fe1c ;
b:000000000064fe18 ;
c:000000000064fe14.
8 bytes.
d:000000000064fe08 ;
e:000000000064fe00 ;
f:000000000064fdf8.
得到什么地址取决于所使用的操作系统及编译器的分配内存方式。
使用%u显示 sizeof 生成的值,因为它是无符号的整数。使用一个新的格式说明符 %p,来输出变量的地址。这个格式说明符指定输出一个内存地址,其值为十六进制。内存地址一般是32位或64位,地址的大小决定了可以引用的最大内存量。在本例使用的计算机上,内存地址是64位,表示为16个十六进制数;在其他机器上,这可能不同。然后,输出double变量占用的字节数,接着输出这3个变量的地址。
事实上,程序本身不如输出那么有趣。看看显示出来的地址,地址值逐渐变小,呈等差排列,如图5-2所示。在本例使用的计算机上,地址b比a低4, c比b低4,这是因为每个long类型的变量占用4个字节。变量d、e、f也是如此,但它们的差是8,这是因为类型double的值用8个字节来存储
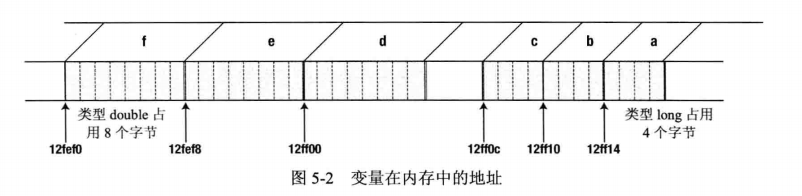
图5-2在变量d和c的地址之间有一个空隙。为什么?许多编译器给变量分配内存地址时,其地址都是变量字节数的倍数,所以4字节变量的地址是4的倍数, 8字节变量的地址是8的倍数。这就确保内存的访问是最高效的。本例使用的计算机在d和c之间有4字节的空隙,使d的地址是8的倍数。如果程序在c的后面定义了另一个long类型的变量,该变量就占用4字节的空隙,于是d和c之间就没有空隙了。
注意:
如果变量地址之间的间隔大于变量占用的字节数,可能是因为程序编译为调试版本。在调试模式下,编译器会配置额外的空间,以存储变量的其他信息,这些信息在程序以调试模式下执行时使用。
下面声明了一个包含4个元素的数组:
long number[4];
数组名称number指定了存储数据项的内存区域地址,把该地址和索引值组合起来就可以找到每个元素,因为索引值表示各个元素与数组开头的偏移量。
声明一个数组时,要给编译器提供为数组分配内存所需的所有信息,包括值的类型和数组维,而值的类型决定了每个元素需要的字节数。数组维指定了元素的个数。数组占用的字节数是元素个数乘以每个元素的字节数。数组元素的地址是数组开始的地址,加上元素的索引值乘以数组中每个元素类型所需的字节数。图5-3是数组变量保存在内存中的情形。
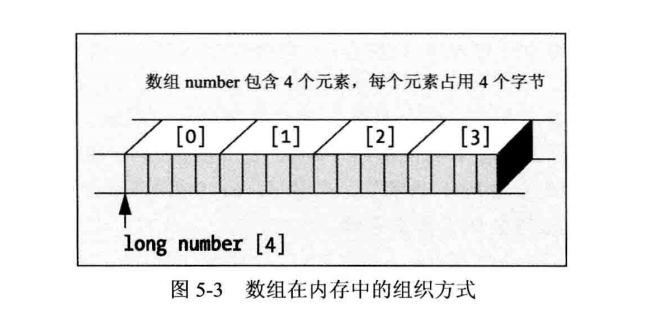
获取数组元素地址的方式类似于普通变量。对value整数变量,可以用以下语句输出它的地址:
printf("\n%p",&value);
要输出number数组的第3个元素的地址,可以编写如下代码:
printf("\n%p",&value[2]);
下面的代码段设置了数组中的元素值,然后输出了每个元素的地址和内容:
int data[5]
for (unsigned int i = 0; i <= 5; ++i) {
data[i] = 12*(i+1);
printf("data[%d] address:%p contents:%d\n",i,&data[i],data[i]);
}
i的值显示在数组名后面的括号中。每个元素的地址都比前一个元素大4,所以每个元素占用4个字节。
当然,可以给数组的元素指定初值,这可能只是为了安全起见。预先确定数组元素的初始值,更便于查找错误。为了初始化数组的元素,只需在声明语句中,在大括号中指定一列初值,它们用逗号分开,例如:
double values[5] = {1.5,2.5,3.5,4.5,5.5};
这个语句声明了一个包含5个元素的数组value, values[0]的初值是1.5, value[1]的初值是2.5,依此类推。要初始化整个数组,应使每个元素都有一个值。如果初值的个数少于元素数,没有初值的元素就设成0。因此如果编写
double values[5] = {1.5,2.5,3.5};
前3个元素用括号内的值初始化,后两个元素初始化为0。
如果没有给元素提供初值,编译器就会给它们提供初值0,所以初值提供了一种把整个数组初始化为0的简单方式。只需要给一个元素提供0:
double values[5] = {0.0};
整个数组就初始化为0.0.
如果初值的个数超过数组元素的个数,编译器就会报错。在指定一列初始值时,不必提供数组的大小,编译器可以从该列值中推断出元素的个数:
double values[] = {1.5,2.5,3.5};
sizeof 运算符可以计算出指定类型的变量所占用的字节数。对类型名称应用sizeof运算符,如下:
printf("%u bytes.\n", sizeof(long));
sizeof 运算符后类型名称外的括号是必需的。如果漏了它,代码就不会编译。也可以对变量应用 sizeof 运算符,它会计算出该变量所占的字节数。
注意
sizeof 运算符生成 size_t 类型的值,该类型取决于实现代码,一般是无符号的整数类型。如果给输出使用%u说明符,编译器又把size_t定义为unsigned long或者unsigned long long,编译器就可能发出警告: %u说明符不匹配print()函数输出的值。使用%zu会消除该警告消息。
sizeof 运算符也可以用于数组。下面的语句声明一个数组:
double values[] = {1.5,2.5,3.5};
printf("%u bytes.\n", sizeof values);
也可以用表达式 sizeof values[0] 计算出数组中一个元素所占的字节数。这个表达式的值是8。当然,使用元素的合法索引值可以产生相同的结果。数组占用的内存是单个元素的字节数乘以元素个数。因此可以用sizeof运算符计算数组中元素的数目:
size_t element_count = sizeof values/sizeof values[0];
执行这条语句后,变量 element_count 就含有数组 values 中元素的数量。element_count 声明为 size_t 类型,因为它是 sizeof 运算符生成的类型。可以将 sizeof 运算符应用于数据类型,所以可以重写先前的语句,计算数组元素的数量,如下所示:
size_t element_count = sizeof values/sizeof (double);
这会得到与前面相同的结果,因为数组的类型是double, sizeof(double)会得到元素占用的字节数。有时偶尔会使用错误的类型,所以最好使用前一条语句。
sizeof 运算符应用于变量时不需要使用括号,但一般还是使用它们,所以前面的例子可以编写为:
可以用 sizeof 计算出的数组元素个数 作为循环变量,防止下标越界。
下面介绍二维数组。二维数组可以声明如下:
float carrots[3][5];
这行语句声明了一个数组carrots,它包含3行5个浮点数元素。注意每一维都放在自己的方括号中。
与田里的蔬菜一样,使这些数组排成矩形会比较方便。把这个数组排成3行5列,它们实际上按行顺序存储在内存中,如图5-4所示。很容易看出,最右边的索引变化地最快。在概念上,左边的索引选择一行,右边的索引选择该行中的一个元素。
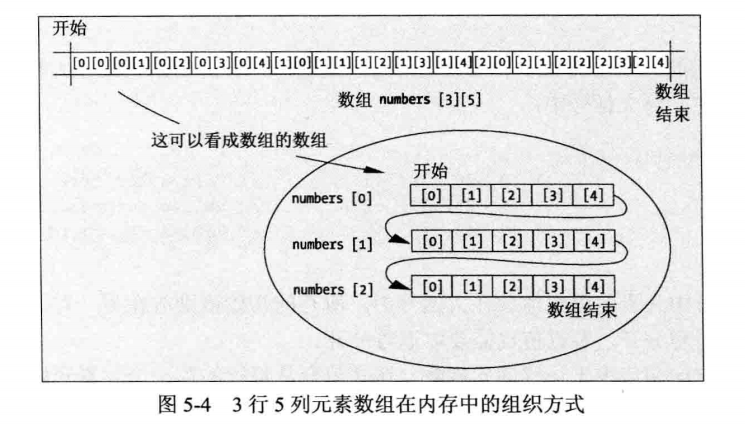
图5-4也说明了如何将二维数组想象成一维数组,其中的每个元素本身是一个一维数组。可以将number数组视为3个元素的一维数组,数组中的每个元素都含有5个float类型的元素。第一行的5个float元素位于标记为numbers[0]的内存地址上,第二行的5·个foat元素位于numbers[1],最后一行的5个元素位于numbers[2]
当然,分配给每个元素的内存量取决于数组所含的变量的类型。double类型的数组需要的内存比float或int类型的数组多。图5-5说明了数组numbers[4][10]的存储方式,该数组有4行10个float类型的元素。
因为数组元素的类型是float,它在机器上占4个字节,这个数组占用的内存总数是4x10×4个字节,即160个字节。
三维数组是二维数组的扩展:
float carrots[4][10][20];
这个语句声明的数组有800个元素,可以把它看作存储豆类植物的产量,豆类植物· 有三块田,每块田包含10行20列植物。根据需要,可以定义任意多维数组。
二维数组的初始化类似于一维数组,区别是把每一行的初始值放在大括号0中,再把所有行放在一对大括号中:
int numbers[3][4]={
{10,20,30,40},
{15,25,35,45},
{47,48,49,50}
};
初始化行中元素的每组值放在大括号中,所有的初始值则放在另一对大括号中。一行中的值以逗号分开,各行值也需要以逗号分开。
如果指定的初值少于一行的元素数,这些值会从每行的第一个元素开始,依序赋予各元素,剩下未指定初值的元素则初始化为0。仅提供一个值,就可以把整个数组初始化为0:
int numbers[3][4]={0};
对于三维或三维以上的数组,这个过程会被扩展。例如三维数组有3级嵌套的括号,内层的括号包含每行的初始值,例如:
int numbers[2][3][4]={
{
{10,20,30,40},
{15,25,35,45},
{47,48,49,50}
},
{
{10,20,30,40},
{15,25,35,45},
{47,48,49,50}
}
};
共 2 * 3 * 4 = 24 个元素。
前面的所有数组都在代码中指定了固定的长度。也可以定义其长度在程序运行期间确定的数组。下面是一个示例:
size_t size = 0;
pintf("输入:");
scan("%zd",&size);
float values[size];
在这段代码中,把从键盘上读取的一个值放在size中。接着使用size的值指定数组array的长度。因为sizet是用实现代码定义的整数类型,所以如果尝试使用%d读取这个值,就会得到一个编译错误。%zd中的z告诉编译器,它应用于size t,所以无论整数类型size t是什么,编译器都会使说明符适用于读取操作。
遵循C11的编译器不必支持变长数组,因为它是一个可选特性。如果编译器不支持它,符号__STDC_ NO_VLA__ 就必须定义为1,使用下面的代码可以检查编译器是否支持变长数组:
#ifdef __STDC_ NO_VLA__
printf("不支持");
exit(1);
这段代码使用了第13章介绍的预处理器指令。如果定义了 STDC NO_VLA_ 符号, print()语句和后面的exit()语句就包含在程序中。如果不支持变长数组,但把这段代码放在main()的开头, printt()函数调用就会显示一个消息,并立即结束程序。