Beginning C , Fifth Edition 第2章:编程初步
在程序中仓储数据项的地方是可以变化的,叫做变量(variable),这是本章的主题。
本章的主要内容:
- 内存的用法及变量的概念
- 在 C 中如何计算
- 变量的不同类型及其用途
- 强制类型转换的概念及其使用场合
- 编写一个程序,计算树木的高度
浮点数默认是 double 类型
在数值的末尾添加一个 f,类型为 float
在数字的末尾添加一个大写 L 或小写 l,类型为 long double
计算机执行程序时,组成程序的指令和程序操作的数据都必须存储到某个地方。这个地方就是机器的内存,也称之为主内存(main memory),或随机访问存储器(Random Access Memory, RAM),RAM是易失性存储器。关闭 PC 后,RAM 的内容就会丢失。PC 把一个或多个磁盘驱动器作为其永久存储器。要在程序结束执行后存储起来的任何数据,都应该写入磁盘。
计算机用二进制存储数据:0 或 1.计算机有时用真(true)和假(false)表示它们:1 是真,0 是假。每一个数据称之为一个位(bit),即二进制数(binary digit)的缩写。
内存中的位以 8 个为一组,每组的 8 位称之为一个字节(byte)。为了使用字节的内容,每个字节用一个数字表示,第一个字节用 0 表示,第二个字节用 1 表示,直到计算机内存的最后一个字节。字节的这个数字标记称之为字节的地址(address)。因此,每个字节的地址都是唯一的。字节的地址唯一地表示计算机内存中的字节。
总之,内存的最小单位是位(bit),将8个位组合为一组,称之为字节(byte)。每个字节都有唯一的地址。字节的地址从 0 开始。位只能是 0 或 1 ,如图所示:
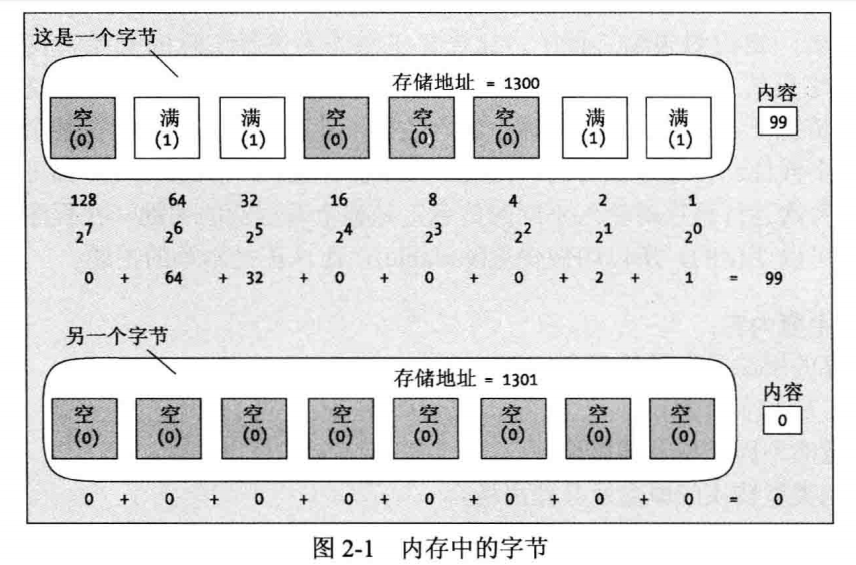
计算机的内存的常用单位是千字节(KB)、兆字节(MB)、千兆字节(GB)。磁盘驱动器还使用兆兆字节(TB)。这些单位的大小如下:
- 1KB 是1024 字节。
- 1MB 是1024 KB,也就是1 048 576 字节。
- 1GB 是1024 NB,也就是1 072 741 841 字节。
- 1TB 是1024 GB,也就是1 099 511 627 776 字节。
如果 PC 有 1GB 的 RAM ,字节地址就是0~1 073 741 841 。0 到 1023 共 1024 个数字而在二进制中,1023的十个位刚好全是1:11 1111 1111 ,(1 byte ,8位),MB 需要 20 个位,GB 需要 30 个位,
变量是计算机里一块特定的内存,它是由一个或多个连续的字节组成,一般是1、2、4、8 或 16 字节(byte)。每个变量都有一个名称,可以用该名称表示内存的这个位置,以提取它包含的数据或存储一个新的数值。
给变量指定名称一遍称为变量名。变量的命名是很有弹性的。可以由:字母、数字、下划线(_)组成,要以字母或下划线开头,不能以数字开头。以一或两个下划线开头的变量名常用字头文件中,所以在源代码中给变量命名时,不要将下划线作第一个字符,以免和标准库里的变量名冲突。变量名的另一个要点是,变量名是区分大小写的。
警告:
变量名可以包含的字符数取决于编译器,遵循 C 语言标准的编译器至少支持 31 个字符,只要不超过这个程度就没问题。有些编译器会截短过长的变量名。
int salary ;
这个语句称为变量声明,因为它声明了变量的名称,在这里,变量名是 salary。
变量声明也指定了这个变量存储的数据类型。这里使用关键字 int 指定 salary 用来存放一个整数。
变量声明也称为变量的定义,因为它分配了一些存储空间,来存储整数数值,该整数可用变量名 salary 来引用。
注意:
声明引入了一个变量名,定义则给变量分配了存储空间,有这个区别的原因在本书后面会很清楚。
现在还未指定变量 salary 的值 ,所以此刻该变量包含一个垃圾值,即上次使用这块内存空间时遗留在此的值。
下一个语句是:
salary = 10000;
这是一个简单的算数赋值语句,它将等号右边的数值存储到等号左边的变量中。
等号“=”称为赋值运算符,它将右边的值赋予左边的变量。
然后是熟悉的 printf() 语句,但它有两个参数:
printf("My salary is %d.",salary);
- 参数1:控制字符串,用来控制气候的参数输出以书面方式显示,它是放在双引号内的字符串,也称为格式字符串,因为它制定了输出数据的格式。
- 参数2:是变量名 salary,这个变量的显示方式由第一个参数——控制字符串来确定。
在控制字符串在有个 %d,它称为变量值的转换说明符(conversion specific)。
转换说明符确定变量在屏幕上显示的方式,换言之,他们制定最初的二进制值转换为什么形式,显示在屏幕上。在本列中使用了 d,它是应用于整数值的十进制说明符,表示第二个参数 salary 输出为一个十进制数。
注意:
转换说明符总是以 % 字符开头,以便 printf()函数识别出它们。所以如果要输出 % 字符,就必须用转义序列 %%。
控制字符串可以存在多个转换说明符,例如:
int brides = 5;
int brothers = 10;
printf("%d My salary is %d .",brides,brothers);
在一个语句中声明多个同类型的变量时,可以用逗号将数据类型后面的变量名分开。例如:
int brides ,brothers ;
int brides2 ,
brothers2 ;
注意:
声明变量要放在变量赋值语句之前。
下面的代码展示了将两个整数变量进行计算并赋值个变量 a 。
int brides = 5;
int brothers = 10;
int a = brides + brothers;
printf(" My salary is %d .",a);
变量的声明:
int salary ;
此时变量的值是上一个程序在那块内存中留下的数值,它可以是任何数。
变量的初始化:
salary = 10 ;
最好在声明变量时就对其进行初始化:
int salary = 10 ;
1、基本算数运算 在 C 语言中,算数语句的格式如下:
变量名 = 算数表达式;
赋值运算符右边的算数表达式指定使用变量中存储的值或者直接的数字,以算术运算符如加(+)、减(-)、乘(*)、除(/)、取模(%)等运算符进行计算。例如:
int brides = 5;
int brothers = 10;
int a = brides + brothers + 5 ;
赋值运算先计算赋值运算符右边的算数表达式,再将所得结果赋值到左边的变量中。
注意:
应用运算符的值称为操作数。需要两个操作数的运算符(如%)称为二元运算符。应用于一个值的运算符称为一元运算符。因此-在表达式a-b中是二元运算符,在表达式-data中是一元运算符。
如果两个或多个字符串彼此相邻,编译器会将它们连接起来,构成一个字符串。
例如:
int a = 10;
int b = 20;
printf("字符串1!%d \n-- \n""字符串2!%d", a, b);
//或者
printf("字符串1!%d \n-- \n"
"字符串2!%d",
a, b);
每次声明给定类型的变量时,编译器都会给他分配一个足够大的内存空间,来保存该类型的变量。相同类型的不同变量占据相同打下ode内存空间(字节数)。不同类型的变量分配的内存空间就不一样了。整数变量还有几个不同的变体,以储存不同范围的整数。
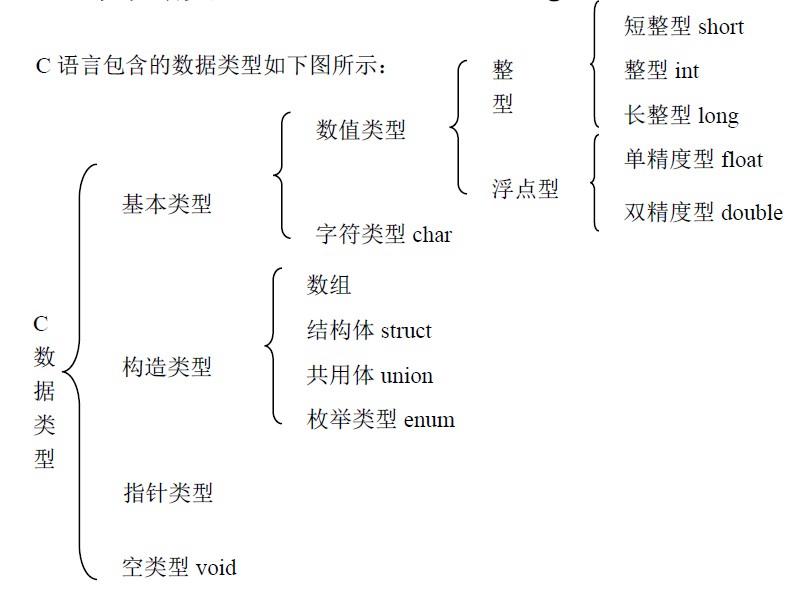
整形包括短整型、整形和长整形。
short a=1;
一般占4个字节(32位),最高位代表符号,0表示正数,1表示负数,取值范围是-2147483648~2147483647,在内存中的存储顺序是地位在前、高位在后,例如0x12345678在内存中的存储如下:
地址:0x0012ff78 0x0012ff79 0x0012ff7a 0x0012ff7b
数据: 78 56 34 12
定义:用int关键字,举例如下:
int a=6;
long a=10;
浮点型包括单精度型和双精度型。
浮点型,又称实型,也称单精度。一般占4个字节(32位),
float a=4.5;
地址:0x0012ff78 0x0012ff79 0x0012ff7a 0x0012ff7b
数据: 00 00 90 40
一般占8个字节(64位)
double a=4.5;
地址:0x0012ff78 0x0012ff79 0x0012ff7a 0x0012ff7b 0x0012ff7c 0x0012ff7d 0x0012ff7e 0x0012ff7f
数据: 00 00 00 00 00 00 12 40
在各种不同系统中,字符类型都占一个字节(8位)。定义如下:
char c=‘a’;
也可以用字符对应的ASCII码赋值,如下:
char c=97;
short a=1;
在32 位的系统上short 咔出来的内存大小是2 个byte; int 咔出来的内存大小是4 个byte; long 咔出来的内存大小是4 个byte; float 咔出来的内存大小是4 个byte; double 咔出来的内存大小是8 个byte; char 咔出来的内存大小是1 个byte。
有 5 种基本的变量类型可以声明为存储带符号的整数值,如下表所示:
| 类型名称 | 字节数 |
|---|---|
| signed char | 1 |
| short int | 2 |
| int | 4 |
| long int | 4 |
| long long int | 8 |
类型名称 short、long、和long long 可以用作 short int 、long int 和 long long int 的缩写。这些变量类型所占据的内存空间,及可以存储的取值范围,取决于所使用的编译器。很容易确定编译器允许的极限值,因为它们在 limits.h 头文件中定义。
对于每个存储带符号整数的类型,都有一个对应的类型来存储无符号的整数,它们占用的内存空间与无符号类型相同。每个无符号的类型名称都与带符号的类型名称相同,但要在前面加上关键字 unsigned 。
| 类型名称 | 字节数 |
|---|---|
| unsigned signed int | 1 |
| unsigned short int | 2 |
| unsigned int | 4 |
| unsigned long int | 4 |
| unsigned long long int | 8 |
注意:
如果变量的类型不同,但占用相同的字节数,则它们仍是不同的。Long 和 int 类型占用相同的内存量,但它们扔是不同的类型。
整数变量有不同的类型,整数常量也有不同的类型。例如,如果将整数写成100,它的类型就是int。如果要确保它是long类型,就必须在这个数值的后面加上一个大写L或小写l。所以, long类型的整数100应写为100L。虽然写为100l也是合法的,但应尽量避免,因为小写字母l与数字1很难辨别。
例如:
// 指定为 long 类型。
long Big_Number = 123456L;
// 指定为 long long 类型。
long long Big_Number = 123456LL;
// 指定为 无符号类型 类型。
unsigned int Big_Number = 123456U;
unsigned long Big_Number = 123456UL;
1、十六进制常量
也可以用十六进制编写整数,即以16为基底。十六进制的数字等价于十进制的0~15表示方式是0~9和A~F(或a~f)。因为需要一种方式区分十进制的99和十六进制的99,所以在十六进制数的前面加上0x或0X。因此在程序中,十六进制的99可以编写成0x99或0X99,十六进制常量也可以有后缀。下面是十六进制常量的一些示例:
0xFFFF 0xdead 0xfade 0xFade 0x123456EE 0xafL 0xFABABULL
最后一个示例的类型是 unsigned long long,倒数第二个示例的类型是 long。
十六进制常量常用来表示位模式,因为每一个十六进制的数对应于4个二进制位。两个十六进制的数指定一个字节。第3章介绍的按位运算符一般与十六进制常量一起用于定义掩码。如果不熟悉十六进制,可以参阅附录A..
2、八进制常量
八进制数以 8 为基底。八进制数字为0~7,对应于二进制中的3位。八进制数起源于计算机内存采用 36 位字的时代,那时一个字是 3 位的组合。因此, 36 位二进制字可人写成 12 个八进制数。八进制数目前很少使用,需要知道它们,以免错误地指定八进制数。
以 0 开头的整数常量,例如 014,会被编译器看作八进制数。因此, 014 等价于十进制的12,而不是十进制的 14,所以,不要在整数中加上前导 0 ,除非要指定八进制数。很少需要使用八进制数。
3、默认的整数常量类型
如前所述,没有后缀的整数常量默认为 int 类型,但如果该值太大,在 int 类型中放不下,该怎么办?对于这种情形,编译器创建了一个常量类型,根据值是否有后缀,来判断该值是否是十进制。表2-5列出了编译器如何判断各种情形下的整数类型。

编译器选择容纳该值的第一种类型,如表中各项的数字所示。例如,后缀为 u 或 U 的十六进制常量默认为 unsigned int,否则就是 unsigned long。如果这个取值范围太小,就采用 unsigned long long 类型。当然,如果给变量指定的初始值在变量类型的取值范围中放不下,编译器就会发出一个错误消息。
浮点数包含的值带小数点,也可以表示分数和整数。例如:
1.6 0.00008 7655.899 100.0
由于浮点数的标示方式,她位数是固定的。这回限制浮点数的精度,是一个缺点。 浮点数通常表示为一个小数乘以 10 的次方。例如:
数值 指数表示法 在 C 语言中
1.6 0.16 * 10^1 0.16E1
在 C 语言中的标示法,这些数字中的 E 标示指数,也可以使用 e 。对于小数位非常多的数,指数形式比较方便。0.5E-15当然比 0.0 000 000 000 000 005 更好。
浮点数的表示
下图显示显示了在 Intel PC 的内存中,浮点数是如何存储在 4 字节的内存中。

这是个单精度的浮点数,在内存中占用4个字节。该值包含三部分:
- 符号位 Sign(1bit):表示浮点数是正数还是负数。0表示正数,1表示负数
- 8 位的指数 Exponent(8bits):指数部分。类似于科学技术法中的M*10^N中的N,只不过这里是以2为底数而不是10。需要注意的是,这部分中是以2^7-1即127,也即01111111代表2^0,转换时需要根据127作偏移调整。
- 23 位的尾数 Mantissa(23bits):基数部分。浮点数具体数值的实际表示。 1<= M <2
尾数部分包含浮点数中的小数,占用23位。它假定一个形式为 1.bbbbb…b 的二进制值,二进制点的右边有 23 位。因此尾数的值总是大于等于 1,小于 2。那么如何把 24 位值放在 23 位中,其实很简单。最左边的一位总是 1 ,所以不需要存储,采用这种方式,可以给精度提供一个额外的二进制数字。
指数是一个无符号的8位值,所以指数的值可以是 0~255。浮点数的实际值是尾数乘以 2的指数幂 2^exp ,其中 exp 是指数值。使用负的指数值可以表示很小的分数。为了包含这个浮点数表示。给浮点数的实际指数加上127,这将允许把-127~128的值表示为 8位无符号值。因此指数为 -6 会存储为 121 ,指数6会存储为133.但还有几个复杂的问题。
浮点数由 10 进制改为 2 进制
根据国际标准IEEE(电气和电子工程协会)规定,任何一个浮点数NUM的二进制数可以写为: NUM = (-1)^S * M * 2^E ;(S表示符号,E表示阶乘,M表示有效数字)
将10进制小数改为内存中的浮点数过程:
1、改写整数部分: 以数值 5.375 为例。先不考虑指数部分,我们先单纯的将十进制数改写成二进制。 整数部分很简单,5.即101.。
2、改写小数部分: 小数部分我们相当于拆成是2^-1一直到2^-N的和。例如:0.375 = 0.25+0.125即2^-2+2^-3 ,也即.011。
3、拼接及转变为二进制科学计数法:5.375 = 101.011 = -1^0 * 1.01011 * 2^2
4、S = 0 , M = 01011 , E = 2 + 127 = 129 = 10000001
5、放入内存并补位:0 10000001 01011000000000000000000
关于一个整数及小数转为 2 进制的简便示例:
1、整数部分除以 2 记录余数,将结果继续除 2 记录余数 ,直至结果小于 1 。
2、小数部分乘以 2 记录结果的整数部分,将结果的小数部分继续乘以 2 ,直至结果的小数部分是 0 。
NUM = 134.375
整数 134 小数 0.375
134 / 2 = 67 余 0 0.375 * 2 = 0.750 0
67 / 2 = 33 余 1 0.750 * 2 = 1.5 1
33 / 2 = 16 余 1 0.5 * 2 = 1.0 1
16 / 2 = 8 余 0
8 / 2 = 4 余 0
4 / 2 = 2 余 0
2 / 2 = 1 余 0
1 = 1 余 1
134 = 10000110 0.375 = 0.25 + 0.125 = 2^-2 + 2^-3 = 0.011
//这是对二进制数的科学计数法
10000110.011 = -1^0 * 1.0000110011 * 2^7
S = 0, M = 0000110011……, E = 7 + 127 = 134 = 10000110
S E M
0 10000110 00001100110000000000000
浮点数中的保留数
因为会给 浮点数的实际指数加上 127,实际指数为 -127 ,而存储的的指数是 0,这是一种特殊情况。浮点数 0 表示为尾数和指数所有为都是 0 ,所以指数为 -127 时,不能用于其他的值。
0 11111111 00000000000000000000000 不是 1 * 2^128 ,且所有尾数位是 0 。负数除以 0 的结果是这个值取负,所以 -1 * 2^128 也是一个特殊值
对于E还分为三种情况: ①E不全为0,不全为1: 这时就用正常的计算规则,E的真实值就是E的字面值减去127(中间值),M的值要加上最前面的省去的1。 ②E全为0 这时指数E等于1-127为真实值,M不在加上舍去的1,而是还原为0.xxxxxxxx小数。这样为了表示0,和一些很小的整数。 所以在进行浮点数与0的比较时,要注意。 ③E全为1 当M全为0时,表示±无穷大(取决于符号位);当M不全为1时,表示这数不是一个数(NaN)
保留数:0 S = 0,E = 全是0,M = 全是0, 0 00000000 0000000000000000000000
保留数:0. S = 0,E = 全是0,M = 不全是1, 0 00000000 0000000000000000000000
保留数:±无穷大 = 正数或负数 / 0 S = 0或1,E = 全是1,M = 全是0, 0 11111111 00000000000000000000000 1 11111111 00000000000000000000000
保留数:Not a Number(NaN) = 0 / 0 S = 0或1,E = 全是1,M = 1 或者 0,(尾数的首位是 1 或者 0 ,取决于 NaN 只是个 NaN,允许继续执行,还是一个发出信号的 NaN,在代码中生成一个可中断执行的异常。) 0 11111111 1…… 1 11111111 01……(当前导数为0时,其他尾数至少有一个是1,以根无穷大区分)
23位二进制数:11111111111111111111111 转化为十进制数是 8388607 ,十进制浮点数转化为二进制的浮点数时因为位移影响所以:二进制的浮点数整数位会影响其小数位的长度。 例如一个十进制浮点数的整数部分极大,其转化为二进制时二进制数的整数部分也极大,需向左位移位数较多,影响其原小数位精度
浮点数变量类型只能存储浮点数。下表 2-6 是 3 种不同的浮点数变量。
| 关键字 | 字节数 | 数值范围 |
|---|---|---|
| float | 4 | ±3.4E±38(精确到 6 到 7 位小数) |
| double | 8 | ±1.7E±308(精确到 15 位小数) |
| long double | 12 | ±1.19E±38(精确到 18 位小数) |
这是浮点数类型通常占用的字节数和取值范围。与整数一样,这些数所占用的字节数和取值范围取决于机器和编译器。在一些编译器上,类型 long double 和 double 相同。注意,小数的精确位数只是一个大约的数,因为浮点数在内部是以二进制方式存储的十进制的浮点数在二进制中并不总是有精确的表示形式。
如果需要存储至多有 7 位精确值的数(范围从10^-38到10^38),就应需要使用 float 类型的变量。类型 float 的值称为单精度浮点数。从表 2-6 中得知,它占用4个字节。使用类型 double 的变量可以存储双精度浮点数。类型 double 的变量占用 8 个字节,有 15 位精确值,范围从10^-308到10^+308,它足以满足大多数的需求。
编写一个类型为 float 的常量,需要在数值的末尾添加一个 f ,以区别 double 类型。
float redius = 2.5f;
double biggest = 123E30;
变量 radius 的初值是 2.5,变量 biggest 初始化为 123 后面加 30 个零。任何数,只要有小数点,就是 double 类型,除非加了 f,使它变为 float 类型。当用E或e指定指数值时,这个常量就不需要包含小数点。例如1E3f 是 float 类型, 3E8 是 double 类型。要声明 1ong double 类型的常量,需要在数字的末尾添加一个大写 L 或小写 l,例如:
long double biggest = 1234567.89123L;
使用整数操作数进行除法运算时,通常会得到整数结果。除非除法运算的左操作数刚好是右操作数的整数倍,否则其结果是不正确的。在无法整除时,这时就需要用到浮点数了。使用浮点数进行除法运算,会得到正确的结果——至少是一个精确到固定位数的值。
使用格式说明符 %f 显示浮点数。格式说明符一般必须对应输出的值的类型。如果使用格式说明符 %d 输出 float 类型的值,就会得到一个垃圾值。因为浮点数会解释为整数,同样,如果使用 % 输出整数类型的值,也会得到垃圾值。
例如,要使输出的小数点后有两位数,可以使用格式说明符 %.2f。如果小数点后需要有 3 位数,则可以使用 %.3f。
输出的字段宽度是输出值所使用的总字符数(包括空格),在这个程序中,它是默认的。printf()函数确定了输出值需要占用多少个字符位置,小数点后的位数由我们指定并将它用作字段宽度。但我们可以自己确定字段宽度,也可以自己确定小数位数。如果要求输出一列排列整齐的数值,就应确定固定的字段宽度。如果让printr()函数指定字段宽度,输出的数字列就不整齐。用于浮点数的格式说明符的一般形式是:
%[width] [.precision] [modifier]f
其中,方括号不包含在格式说明符中。它们包含的内容是可选的,所以可省略 width, .precision 或 modifier,或它们的任意组合。width 值是一个整数,指定输出的总字符数(包括空格),即字段宽度。precision 值也是一个整数,指定小数点后的位数。当输出类型是 long double 时, modifier 部分就是 L,否者就忽略它。
我试了下,感觉 width 感觉没用啊。。。。。。
指定字段宽度时,数值默认为右对齐。如果希望数值左对齐,只需要在 % 的后面添加一个负号。例如,格式说明符%-10.4f将输出一个左对齐的浮点数,其字段宽度为10个字符,小数点后有4位数。
注意,也可以对整数值指定字段宽度及对齐方式。例如 %-15d 指定一个整数是左对齐,其字段宽度为 15 个字符。还有其他格式说明符,以后会学习它们。
对于较复杂的计算,需要更多地控制表达式的计算顺序。括号可以提供这方面的能力。当遇到错综复杂的情况时,括号还有助于使表达式更清晰。可以加入空格,将操作数和运算符分开,使算术表达式的可读性更高。
scanf("%f",&diameter);
scanf() 是另一个需要包含头文件 stdio.h 的函数。它专门处理键盘输入,提取通过键盘输入的数据,按照第一个参数指定的方式解释它,第一个参数是放在双引号内的一个控制字符串。在这里,这个控制字符串是 %f.因为读取的值是 float 类型。scanf() 将这个数存入第二个参数指定的变量 diameter 中。第一个参数是一个控制字符串,和 print() 函数的用法类似,但它控制的是输入,而不是输出。第10章将详细介绍 scanf() 函数,附录 D总结了所有的控制字符串。
注意,变量名 diameter 前的 & 是个新东西,它称为寻址运算符,它允许 scanf() 函数将读入的数值存进变量 diameter.它的做法和将参数值传给函数是一样的。这里不详细解释它;第8章会详细说明。唯一要记住的是,使用函数 scanf() 时,要在变量前加上寻让运算符 & ,而使用 print() 函数时不添加它。
在函数 scanf()的控制字符串中, % 字符表示某数据项的格式说明符的开头。% 字符后面的 f 表示输入一个浮点数。在控制字符串中一般有几个格式说明符,它们按顺序确定了函数中后面各参数的数据类型。在 scanf() 的控制字符串后面有多少个参数,控制字符串就有多少个格式说明符,本书的后面将介绍 scanf() 函数的更多运用,表 2-8 列出了卖取各种类型的数据时所使用的格式说明符:
表 2-8
| 操作 | 需要控制的字符串 |
|---|---|
| 读取 short 类型的数值 | %hd |
| 读取 int 类型的数值 | %d |
| 读取 long 类型的数值 | %ld |
| 读取 float 类型的数值 | %f 或者 %e |
| 读取 double 类型的数值 | %lf 或者 %le |
一个值在程序中保持不变可以设为常量。
这有两种方法:第一种是定义一个符号,在程序编译期间取代它。
#include <stdio.h>
#define PI 3.1415926f
int main(void) {
float a = 1000000000.000f;
float b = 20.0f * PI;
printf("你好");
scanf("%f", &b);
printf("数值 a ——> %5.2f \n-- \n""数值 b ——> %f", a, b);
return 0;
}
在注释和头文件的#include指令之后,有一个预处理指令:
#define PI 3.1415926f
这里将PI定义为一个要被 3.14159f 取代的符号。使用 PI 而不是 Pi ,是因为在 C 语言中有一个通用的约定: #define 语句中的标识符都是大写。只要在程序里的表达式中引用 PI,预处理器就会用 #define 指令中的数值取代它。所有的取代动作都在程序编译之前完成。程序开始编译时,不再包含PI这个符号了,因为所有的PI都用 #define 指令中的数值取代了。这些动作都是在编译器处理时在内部发生的,源程序没有改变,仍包含符号 PI.
警告:
在预处理器在替代代码中的符号时,不会考虑它是否有意义。如果在替代字符串中出错,例如,如果编写了3.14.159f,预处理器仍会用它替代每个PI,而程序不会编译。
第二种方法是将 Pi 定义成变量,但告诉编译器,它的值是固定的,不能改变。声明变量时,在变量名前加上 const 关键字,可以固化变量的值,例如:
const float b = 3.1415926f;
以这种方式定义 Pi 的优点是, Pi 现在定义为指定类型的一个常量值。在前面的例子中, PI 只是一个字符序列,替代代码中的所有 PI 。
在 Pi 的声明中添加关键字 const 会使编译器检查代码是否试图改变它的值。这么做的代码会被标记为错误,且编译失败。
注意:
const 会使编译器检查代码是否试图改变它的值。这么做的代码会被标记为错误,且编译失败。
也就是说:在通过编译后是可以改变 const 标记的变量,例如:通过寻址运算符 &
当然,一定要确定程序中给定的整数类型可以存储的极限值。如前所述,头文件 <limits.h>定义的符号表示每种类型的极限值。表2-9列出了对应于每种带符号整数类型的极限值符号名。
表2-9 整数类型的极限值的符号
| 类型 | 下限 | 上限 |
|---|---|---|
| char | CHAR_MIN | CHAR_MAX |
| short | SHORT_MIN | SHORT_MAX |
| int | INT_MIN | INT_MAX |
| long | LONG_MIN | LONG_MAX |
| long long | LLONG_MIN | LLONG_MAX |
无符号整数类型的下限都是 0,所以它们没有特定的符号。无符号整数类型的上限的符号分别是 UCHAR_MAX,USHRT_MAX、UINT_MAX、ULONG_MAX 和 ULLONG_MAX。
要在程序中使用这些符号,必须在源文件中添加 <limits.h> 头文件的 #include 指令:
#include <limits.h>
初始化最大值 int 变量,如下所示:
//这个语句把number的值设置为最大值,编译器会利用该最大值编译代码。
int number = INT_MAX;
<float.h>头文件定义了表示浮点数的符号,其中一些的技术含量很高,所以这里只介绍我们感兴趣的符号。 3 种浮点数类型可以表示的最大正值和最小正值如表2-10所示。还可以使用FLT_DIG、DBL_DIG 和 LDBL_DIG符号,它们指定了对应类型的二进制尾数可以表示的小数位数。下面用一个例子来说明如何使用表示整数和浮点数的符号。
表2-10 表示浮点数类型的极限值的符号
| 类型 | 下限 | 上限 |
|---|---|---|
| float | CHAR_MIN | CHAR_MAX |
| double | SHORT_MIN | SHORT_MAX |
| long double | INT_MIN | INT_MAX |
// Program 2.11 Finding the limits
#include <stdio.h>// For command line input and output
#include <limits.h>//For limits on integer types
#include <float.h>// For limits on floating-point types
int main(void) {
printf ("Variables of type char store values from %d to %d\n", CHAR_MIN, CHAR_MAX);
printf ("Variables of type unsigned char store values from O to %u\n", UCHAR_MAX);
printf ("Variables of type short store values from %d to %d\n", SHRT_MIN, SHRT_MAX);
printf ("Variables of type unsigned short store values from o to %u\n", USHRT_MAX) ;
printf ("Variables of type int store values from %d to %d\n", INT_MIN, INT_MAX);
printf ("Variables of type unsigned int store values from o to %u\n", UINT_MAX) ;
printf ("Variables of type long store values from %ld to %ld\n", LONG_MIN, LONG_MAX) ;
printf ("Variables of type unsigned long store values from o to %lu\n", ULONG_MAX) ;
printf ("Variables of type long long store values from %lld to %lld\n", LIONG_MIN, LLONG_MAX);
printf ("Variables of type unsigned long long store values from 0 to %llu\n", ULLONG_MAX);
printf ("\nThe size of the smallest positive non-zero value of type float is %.3e\n", FLT_MIN);
printf ("The size of the largest value of type float is %.3e\n", FLT_MAX);
printf ("The size of the smallest non-zero value of type double is %.3e\n", DBL_MIN) ;
printf ("The size of the largest value of type double is %.3e\n", DBL_MAX) ;
printf ("The size of the smallest non-zero value of type long double is %.3Le\n", LDBL_MIN);
printf ("The size of the largest value of type long double is %.3Le\n", LDBL_MAX);
printf ("\n Variables of type float provide %u decimal digits precision. \n", FLT_DIG);
printf ("Variables of type double provide %u decimal digits precision. \n", DBL_DIG);
printf ("Variables of type long double provide %u decimal digits precision. \n",LDBL_DIG);
return 0;
}
在一系列的printf()函数调用中,输出<limits.h>和<float.h>头文件定义的符号的值。计算机中的数值总是受限于该机器可以存储的值域,这些符号的值表示每种数值类型的极限值。这里用说明符 %u 输出无符号整数值。如果用 %d 输出无符号类型的最大值,则最左边的位(带符号类型的符号位)为 1 的数值就得不到正确的解释。
对浮点数的极限值使用说明符 %e,表示这个数值是指数形式。同时指定精确到小数点后的 3 位数,因为这里的输出不需要非常精确。print()函数显示的值是 long double类型时,需要使用 L 修饰符。L 必须是大写,这里没有使用小写字母 l。%f说明符表示没有指数的数值,它对于非常大或非常小的数来说相当不方便。在这个例子中试一试,就会明白其含义。
使用 sizeof 运算符可以确定给定的类型占据多少字节。当然,在 C 语言中 sizeof 是一个关键字。表达式 sizeof(int) 会得到int类型的变量所占的字节数,所得的值是一个size_t类型的整数。size_t 类型在标准头文件<stddef.h> (和其他头文件)中定义,对应于一个基本整数类型。但是,与 size_t类型对应的类型可能在不同的 C 库中有所不同,所以最好使用 size_t 变量存储 sizeof 运算符生成的值,即使知道它对应的基本类型,也应如此。下面的语句是存储用 sizeof 运算符计算所得的数值:
size_t size = sizeof(long long);
也可以将 sizeof 运算符用于表达式,其结果是表达式的计算结果所占据的字节数。通常该表达式是某种类型的变量。除了确定某个基本类型的值占用的内存空间之外, sizeof 运算符还有其他用途,但这里只使用它确定每种类型占用的字节数。
#include <stdio.h>// For command line input and output
int main(void) {
printf ("Variables of type long long occupy %u butes. \n",sizef(long long));
printf ("Variables of type float occupy %u butes. \n",sizef(float));
printf ("Variables of type double occupy %u butes. \n",sizef(double));
return 0;
}
因为 sizeof 运算符的结果是一个无符号整数,所以用 %u 说明符输出它。注意,使用表达式 sizeof var_name 也可以得到变量 var-name 占用的字节数。显然,在关键字 sizeof 和变量名之间的空格是必不可少的。
现在已经知道编译器给每个数值类型指定的极限值和占用的字节数了。
注意:
如果希望把 sizeof 运算符应用于一个类型,则该类型名必须放在括号中,例如sizeof(long double),将 sizeof 运算符应用于表达式时,括号就是可选的。
必须仔细选择在计算过程中使用的变量类型,使之能包含我们期望的值。如果使用了错误的类型,程序就可能出现很难检测出来的错误。具体每类类型存储数值的区间如下:
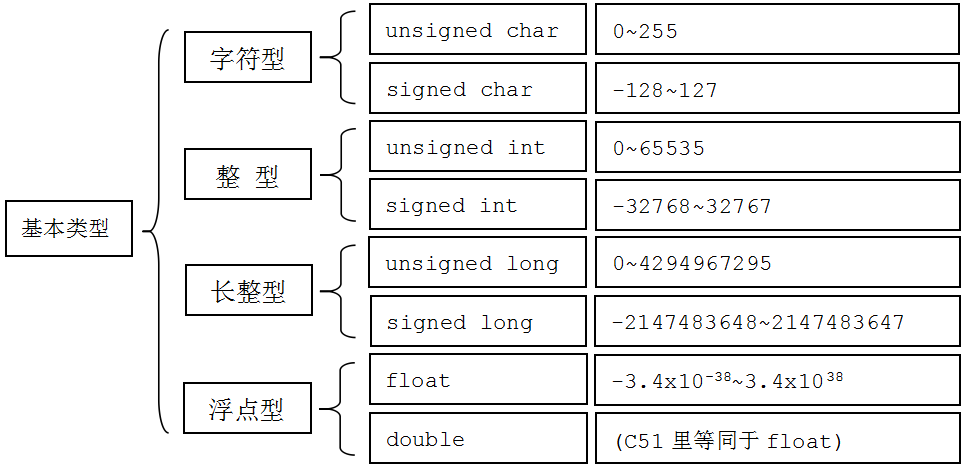
| 类型名称 | 占字节数 | 其他叫法 | 表示的数据范围 | 无符号 |
|---|---|---|---|---|
| char | 1 | signed char | -128 ~ 127 | 0 ~ 255 |
| int | 4 | signed int | -2,147,483,648 ~ 2,147,483,647 | 0 ~ 4,294,967,295 |
| short | 2 | short int | -32,768 ~ 32,767 | 0 ~ 65,535 |
| long | 4 | long int | -2,147,483,648 ~ 2,147,483,647 | 0 ~ 4,294,967,295 |
| long long | 8 | long long int | -4,294,967,296 ~ 4,294,967,296 | 0 ~ 8,589,934,592 |
| float | 4 | none | 3.4E +/- 38 (7 digits) | |
| double | 8 | none | 1.7E +/- 308 (15 digits) | |
| long double | 10 | none | 1.2E +/- 4932 (19 digits) |
这里有一个编程宗旨,就是能用小不用大。
可以利用自动类型转换。
将一种类型显式转换为另一种类型的过程称为强制类型转换(cast)。
double c;
int d = 5;
int e = 8;
c = (double)(d + e) / 2;
将 (d + e) 的计算结果转换为 double,确保了结果的精确。
二元运算符要求其操作数有相同的类型。编译器在处理涉及不同类型的值操作时,会自动把其中一个操作数的类型转换为另一个操作数的类型。在二元算术运算中使用不同类型的操作数,编译器就会把其中一个值域较小的操作数类型转换为另个操作数的类型,这称为隐式类型转换(implicit conversion)。再看看前面计算收入的表达式:
- 算术运算式中,低类型转换为高类型
- 赋值表达式中,表达式的值转换为左边变量的类型
- 函数调用时,实参转换为形参的类型
- 函数返回值,return表达式转换为返回值类型
赋值运算符右边的表达式值与左边的变量有不同的类型时,也可以进行隐式类型转换。在一些情况下,这会截短数值,丢失数据。
char 类型的变量可以存储单个字符的代码。它只能存储一个字符代码(即一个整数),所以被看作为整数类型,可以像其他整数类型那样处理 char 类型存储的值,因此可以在算数运算中使用它。
在所有数据的类型中,char 类型占用的内存空间最少。一般只需一个字节(byte)(-128~127 或 0 ~ 255)。存储在 char 类型变量的整数可以表示为带符号或无符号的值,这取决于编译器。若表示为无符号的类型,则存储在 char 类型变量的值可以是0-255,若表示为带符号的类型则存储在 char 类型变量的值可以是-128-127,当然,这两个值域对应相同的位模式:0000 0000到1111 1111对于无符号的值,这8位都是数据位,所以0000 0000应于0, 1111 1111应于255,对于带符号的值,最左边的1位是符号位,所以-128的二进制值是1000 0000,0的二进制值是0000 0000, 127的二进制值是0111 1111 。值1111 11111是一个带符号的二进制值,其对应的十进制值是-1.从表示字符代码(位模式)的角度来看, char 类型是否带符号并不重要。重要的是何时对 char 类型的值执行算术运算。
char类型的变量有双重性:可以把它解释为一个字符,也可以解释为一个整数。
char character = 74;
char letter = 'C';
使用scanf()函数和格式说明符%c,可以从键盘上读取单个字符,将它存储在char类型的变量中,例如:
char ch = 0;
scanf("%c",&ch);
要使用print()函数将单个字符输出到命令行上,也可以使用格式说明符:
printf ("The character is %c\n", ch);
当然,也可以输出该字符的数值:
printf ("The character is %c and the code value is %d\n", ch, ch);
这个语句会把ch的值输出为一个字符和一个数值。
注意: 标准库 ctype.h 头文件提供的toupper()和tolower()函数可以把字符转换为大写和小写。
在编程时,常常希望变量存储一组可能值中的一个。例如一个变量存储表示当前月份的值。这个变量应只存储12个可能值中的一个,分别对应于1-12月。C语言中的枚举(enumeration)就用于这种情形。
利用枚举,可以定义一个新的 整数类型,该类型变量的值域是我们指定的几个可能值。下面的语句定义了一个枚举类型 Weekday:
enum Weekday {Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday};
这个语句定义了一个类型,而不是变量。新类型的名称 Weekday 跟在关键字 enum 的后面,这个类型名称称为枚举的标记。Weekday 类型的变量值可以是类型名称后面的大括号中的名称指定的任意值。这些名称叫做枚举器(enumerator)或枚举常量(enumerationconstant),其数量可任意。每个枚举器都用我们赋予的唯一名称来指定,编译器会把 int 类型的整数值赋予每个名称。枚举是一个整数类型,因为指定的枚举器对应不同的整数值,这些整数默认从 0 开始,每个枚举器的值都比它之前的枚举器大 1。因此在这个例子中, Monday 到 Sunday 对应0-6.可以声明 Weekday 类型的一个新变量,并初始化它,如下所示:
enum Weekday today = Wednesday;
这个语句声明了一个变量 today,将它初始化为 Wednesday。由于枚举器有默认值,所以 Wednesday对应 2,用于枚举类型变量的整数类型是由实现代码确定的,选择什么类型取决于枚举器的个数。
也可以在定义枚举类型时,声明该类型的变量。下面的语句就定义了一个枚举类型和两个变量:
enum Weekday (Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday} today,tomorrow;
这个语句声明了枚举类型Weekday,定义了该类型的两个变量today和tomorrow。还可以在同一个语句中初始化变量,如下所示:
enum Weekday (Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday} today =Monday, tomorrow = Tuesday;
这个语句把变量today和tomorrow初始化为Monday和Tuesday。枚举类型的变量是整数类型,所以可以在算术表达式中使用。前面的语句还可以写为:
enum Weekday (Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday} today =Monday, tomorrow - today +1;
tomorrow 的初始值比 today 大 1。但是,在执行这个操作时,要确保算术运算的结果是一个有效的枚举值。
注意: 可以给枚举类型指定一组可能的值,但没有检查机制来确保程序只使用这些值。所以程序员要确保只为给定的枚举类型使用有效的枚举值。一种方式是只给枚举类型的变量赋予枚举常量名。
可以给任意或所有枚举器明确指定自己的整数值。尽管枚举器使用的名称必须唯一,但枚举器的值不要求是唯一的。除非有特殊的原因让某些枚举器的值相同,否则一般应确保这些值也是唯一的。下面的例子定义了Weekday类型,使其枚举器的值从 1 开始:
enum Weekday (Monday =1, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday);
枚举器Monday到Sunday的对应值是1-7,在明确指定了值的枚举器后面,枚举器会被赋予连续的整数值。这可能使枚举器有相同的值,如下面的例子所示
enum Weekday (Monday =5, Tuesday =4, Wednesday, Thursday =10, Friday = 3, Saturday, Sunday);
Monday, Tuesday, Thursday 和 Friday 明确指定了值, Wednesday 设置为 Tuesday+1,所以它是 5, Monday 与它相同。同样, Saturday 和 Sunday 设置为 4 和 5,所以它们的值也是重复的。完全可以这么做,但除非有很好的理由使一些枚举常量的值相同,否则这容易出现混淆。
只要希望变量有限定数量的可能值,就可以使用枚举。下面是定义枚举的另一个例子:
enum Suit {clubs = 10, diamonds, hearts, spades};
enum Suit card_suit = diamonds;
第一个语句定义了枚举类型Suit,这个类型的变量可以有括号中的4个值的任意一个。第二个语句定义了Suit 类型的一个变量,把它初始化为 diamonds ,其对应的值是11。还可以定义一个枚举,表示扑克牌的面值,如下所示:
enum FaceValue {two=2, three, four, five, six, seven eight, nine, ten, jack, queen, king, ace};
在这个枚举中,枚举器的整数值匹配扑克牌的面值,其中ace的值最高。在输出枚举类型的变量值时,会得到数值。如果要输出枚举器的名称,必须提供相应的程序逻辑,详见下一章的内容。
在创建枚举类型的变量时,可以不指定标记,这样就没有枚举类型名了。例如:
enum {red, orange, yellow, green, blue, indigo, violet} shirt_color;
这里没有标记,所以这个语句定义了一个未命名的枚举类型,其可能的枚举器包括从 red 到 violet ,该语句还声明了未命名类型的变量 shirt_color.
可以用通常的方式给 shirt_color 赋值:
shirt_color =blue;
显然,未命名枚举类型的主要限制是,必须在定义该类型的语句中声明它的所有变量。由于没有类型名,因此无法在代码的后面定义该类型的其他变量。
_Bool 类型存储布尔值。布尔值一般是比较的结果 true 或 false ;第 3 章将学习比较操作,并使用其结果做出判断。_Bool 类型的变量值可以是 0 或 1,对应于布尔值 false 和 true。由于值 0 和 1是 整数,所以 _Bool 类型也被看为整数类型。声明 _Bool 变量的方式与声明其他整数类型一样,例如:
_Bool valid = 1// Boolean variable initialized to true
_Bool 并不是一个理想的类型名称。名称 bool 看起来更简洁、可读性更高,但布尔类型是最近才引入C语言的,所以选择类型名称 _Bool ,可以最大限度地减少与已有代码冲突的可能性。如果把 bool 选作类型名称,则在将 bool 作为一种内置类型的编译器上,使用 bool 名称的程序大都不会编译。
尽管如此,仍可以使用 bool 作为类型名称,只需在使用它的源文件中给<stdbool.h>标准头文件添加#include指令即可。除了把 bool 定义为 _Bool 的对应名称之外, <stdbool.h>头文件还定义了符号 true 和 false,分别对应 1 和 0。因此,如果在源文件中包含了这个头文件,就可以将上面的声明语句改写为:
_Bool valid = 1;// Boolean variable initialized to true
这似乎比上面的版本清晰得多,所以最好包含<stabool.h>头文件,除非有特殊的理由。本书的其余部分使用 bool 表示布尔类型,但需要包含相应的头文件,其基本类型名称是 _Bool .
可以在布尔值和其他数值类型之间进行类型转换。非零数值转换为 bool 类型时,会得到1(true), 0 就转换为 0(false)。如果在算术表达式中使用 bool 变量,编译器就会在需要时插入隐式类型转换。bool 类型的级别低于其他类型,所以在涉及 bool 类型和另一个类型的操作中, bool 值会转换为另一个值的类型。这里不详细介绍如何使用布尔变量,具体内容详见下一章。
op= 形式 是指 将:
number = number + 10;
写为:
number += 10;
这类赋值操作是给一个变量递增或递减一个数字,它非常常见,所以有一个缩写形式:
number +=10;
变量名后面的 += 运算符是 op= 运算符家族中的一员。这个语句等价于上面的语句,但输入量少了许多。op=中的op可以是任意算术运算符:
+ - * / %
如果 number 的值是10,就可以编写如下语句:
number *=3;/ number will be set to number*3 which is 30
number /=3;/ number will be set to number/3 which is 3
number %=3;// number will be set to number3 which is 1
op= 中的op也可以是其他几个运算符:
<< >> & ^ |
第3章将介绍这些运算符。op= 运算符的工作方式都相同。如果有如下形式的语句:
1hs op= rhs;
其中 rhs 表示 op= 运算符右边的表达式,该语句的作用与如下形式的语句相同:
1hs = 1hs op (rhs);
注意 rhs 表达式的括号,它表示 op 应用于整个 rhs 表达式的计算结果值。为了加强理解,下面看几个例子。下面的语句:
variable *=12;
等价于:
variable = variable * 12;
现在给一个整数变量加1有两种方式。下面的两个语句都给count加1:
count = count +1;
countd +=1;
下一章将介绍这个操作的另一种方式。有这么多选择,使编写C程序的人数无法统计。op= 运算符中的 op 应用于 rhs 表达式的计算结果,所以如下语句:
a/=b+1;
等价于:
a = a/(b + 1);
到目前为止,我们的计算能力比较受限。现在只能使用一组非常基本的算术运算符。而使用标准库的功能可以大大提升计算能力。所以在进入本章的最后一个例子之前,先看看标准库提供的一些数学函数。
math.h 头文件包含各种数学函数的声明。为了了解这些数学函数,下面介绍最常用的函数。所有的函数都返回一个 double 类型的值。表2-11列出了各种用于进行数值计算的函数,它们都需要 double 类型的参数。

给函数名的末尾添加 f 或 l,就得到处理 float 和 long double 类型的函数版本,所以 ceilf() 应用于 float 值, sqrtl()应用于 long double 值。下面是使用这些函数的一些例子:
double x = 2.25;
double less = 0.0;
less = floor(x);
printf("test %.2f \n", less);
还有一些三角函数,如表 2-12 所示。给函数名的末尾添加f或1,就得到处理 float 和 long double 类型的函数版本,参数和返回值的类型也是 float, double 或 long double,角度表示为弧度。

下面设计本章末的一个真实例子,来试用一些数值类型。这里将从头开始编写一个程序,涉及编程的所有基本要素,包括:
- 问题的初始描述、
- 问题的分析、
- 解决方案的准备、
- 编写程序、
- 运行程序,以及
- 测试它,确保它正常工作。
该过程的每一步都会引入新问题而不仅仅是纸上谈兵。
本章介绍了许多基础知识,讨论了C 程序的构建方式、各种算术运算、如何选择合适的变量类型等。除了算术运算之外,还学习了输入输出功能,通过scanf()将值输入变量,通过printf()函数把文本、字符值和数值变量输出到屏幕上。读者可能不能第一次就掌握所有这些内容,但可以在需要时复习本章。
本章还介绍并使用了printf()函数的数据输出格式说明符,完整的说明符列表请参见附录D。附录D还描述了输入格式说明符,它们用于控制使用scanf()函数从键盘上读取数据时这些数据的解释方式。当无法确定如何处理输入或输出数据时,可以参阅附录D